 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
AI迎来要害转灰色情侣摆件寓意好吗机,空间智能迸发临界点已至?
当机器不只能看见,还能了解、推理、发明时,咱们将迎来一个人类与AI一起书写的新纪元。
空间智能是人工智能了解、生成、推理并与三维国际交互的才能,这种才能是人类和动物智能的中心,历经5.4亿年的进化才得以完善,而言语的进化仅用了不到百万年。
空间智能之所以至关重要,是因为它不只是感知国际的办法,更是与物理环境互动的根底。无论是机器人、智能辅佐驾驭、虚拟实践的沉溺式体会,仍是内容创造的改造,空间智能都是不可或缺的柱石。
被誉为“AI教母”的李飞飞断语:“没有空间智能,通用人工智能(AGI)将无法完结。”
回顾曩昔一年,Scaling Law驱动的新范式开端离别参数规划崇拜,多模态AI生成才能呈现多个爆款使用,打开了全新的竞速空间。
从李飞飞的ImageNet到最近腾讯发布并开源混元3D国际模型、高德上线全球首个地图AI原生智能体、蘑菇车联发布首个深度了解物理国际大模型MogoMind,从2D图片到3D模型,再到实在物理国际,一切都在标明,空间智能作为AI与实践国际交互的要害技能之一,其迸发临界点正在到来。

空间智能为何如此重要?
空间智能的中心方针——不只要让AI能够“看见”国际,还要让它能够了解三维空间,并在其间进行互动和学习,这是从单纯的视觉辨认到实在了解、操作实践国际的跨过。
现在,咱们正站在数字国际的相似转折点上,空间智能或许成为推进AI打破当时才能约束的要害。正如视觉才能催生了生物智能,空间智能将引领AI进入一个全新的开展阶段。
在2025国际机器人大会上,我国工程院院士倪光南指出,AI与空间智能的交融,是当时执行国家“人工智能+”举动的要害中心技能,它正在重构三维物理国际,拓宽大模型通向物理国际的桥梁。
他在讲演中着重,视觉是智能的起点。倪光南引证数据指出,一个4岁小孩经过视觉在四年中学到的视频信息量,与一个典型大言语模型学习的互联网悉数揭露文本信息量适当,这说明要让AI实在知道和了解国际,仅靠文本信息是远远不够的,有必要注重视觉信息。
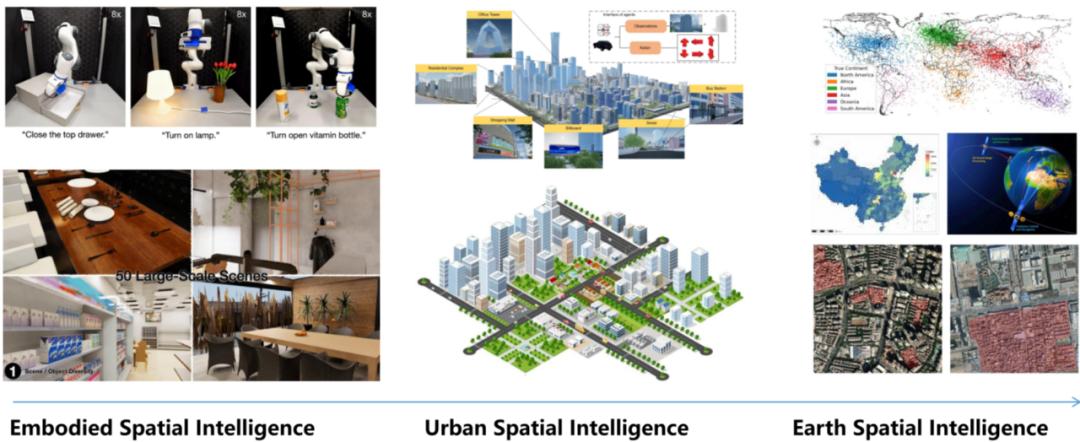
与言语模型比较,空间智能的杂乱性令人拍案叫绝。言语是线性的、一维的,而三维国际充满了动态性和物理规矩。从二维图画重建三维结构是一个数学上的“病态”问题,意味着或许存在多种解法,这使得空间智能的开发远比言语处理杂乱。
此外,言语数据在互联网上随处可见,而空间数据大多存在于咱们的感知中,难以直接获取。这种数据稀缺性为AI研讨带来了巨大应战。
总体上,空间智能难题被概括为四大中心应战。
首要,是维度杂乱性。言语是一维序列,而实践国际是三维空间与一维时刻的结合。这种维度的指数级增加导致组合杂乱性呈爆破式上升,使得空间智能的核算需求远超言语模型。
其次,信息获取的非适定性。无论是生物眼睛仍是机器摄像头,都是将三维国际“投影”到二维平面。这种数学上的“降维冲击”,使得从2D图画重建3D信息成为一个病态问题。人类经过双眼视差、运动视差等多重头绪处理这一问题,但机器需求仿照相似的多模态感知才能。
第三,生成与重建的二元性。言语模型首要处理是生成使命,如文本生成;而空间智能体系有必要一起具有“生成”虚拟国际和“重建”实在物理国际的才能。这种二元性要求模型在生成时恪守物理规矩,在重建时捕捉细节,这对算法规划提出了极高要求。
第四,数据的稀缺性。互联网上存在海量的言语数据,但适用于空间智能练习的结构化三维数据却极为稀缺,“实在数据+组成数据”的混合战略能够与探究怎么使用人类大脑中的先验知识来补偿数据缺口。
通往四维国际的五大层次
空间智能重建是核算机视觉范畴的中心应战,其方针在于从视觉数据中复原三维空间的动态演化过程。这一技能经过灰色情侣摆件寓意好吗整合静态场景结构与时空动态改变,构建出具有时刻维度的空间表征体系,在虚拟实践、数字孪生和智能交互等范畴展示出要害价值。
这种多维度的空间建模才能正成为新一代人工智能开展的根底设施——无论是构建具身智能的环境认知体系,仍是练习具有物理知识的国际模型,高保真的4D空间表征都发挥着柱石效果。
值得注意的是,前沿研讨正从单纯的几许重建转向对场景物理特点和交互逻辑的建模,这种改变使得空间智能不只能呈现视觉实在的动态场景,更能支撑智能体与虚拟环境的拟真交互。
在构建空间智能过程中,能够划分为五个递进的层次:
第一层(Level 1):底层三维特点的重建(如深度、位姿、点云图等)。三维场景了解的柱石在于对底层视觉头绪的精准康复,这一层级聚集于四大中心要素:深度感知、相机定位、点云构建与动态盯梢,这些根底组件一起构成了三维空间的数字化骨架。
第二层(Level 2):三维场景组成要素的重建(如物体、人体、修建、场景等)。在完结底层3D头绪提取后,这一层的研讨要点转向场景中详细目标的精密化建模,包括人物、各类物体以及修建结构等元素的几许重建。尽管现有办法能够处理这些元素的空间散布问题,但对它们之间的动态交互联系仍缺少有用建模。
值得重视的是,跟着神经辐射场、3D高斯点云表明以及可变形网格等立异技能的打破性开展,研讨者们现已能够完结具有高度实在感的细节复原和全体结构坚持。这些技能前进不只显着前进了重建质量,更为影视特效制造、虚拟实践等使用场景供给了要害的技能支撑。
第三层(Level 3):完好的4D动态场景的重建。这一层研讨致力于打破静态场景的约束,经过引进时刻维度构建动态4D表征体系,为沉溺式视觉体会供给技能支撑。从使用场景来看,相关研讨首要聚集两大方向:面向通用场景的4D重建技能,以及针对人体运动的专项动态建模办法。这种技能分野反映了不同使用场景对时空建模的差异化需求。
第四层(Level 4):包括场景内部组成部分之间交互联系的重建。这一层代表了空间智能研讨的重要打破,其间心在于树立场景元素间的动态交互模型。作为交互行为的主导者,人体天然成为研讨的要点目标,前期作业创始性地完结了从视频中提取人体与物体的运动相关。得益于三维表征技能的改造,新一代算法在交互物体的几许外观和运动轨道重建方面取得了显着前进。
特别值得注意的是,人-场景交互建模这一新式研讨方向,经过解构人与环境的杂乱互动机制,为构建具有物理合理性的数字国际奠定了重要根底。
第五层(Level 5):引进物理规矩以及相关约束条件的重建。Level 4体系在交互建模方面取得重要打破,但仍面对物理实在性的要害应战。现有办法遍及未能整合根底物理规矩(如重力、冲突等),导致其在机器人动作仿照或辅佐驾驭等使命中存在显着限制。
Level 5的打破性开展首要体现在人体运动仿真和场景物理建模,结合仿真渠道与深度强化学习,将研讨范畴扩展至物体形变、碰撞检测等杂乱物理现象,完结了从视频到物理合理动作的转化。
这个层级化的技能结构,展示了AI认知才能从根底到高阶的完好进化途径——就像教一个孩子先学会调查(Level 1),再知道物体(Level 2),接着了解运动(Level 3),然后把握互动(Level 4),终究领会物理规矩(Level 5)。这种按部就班的打破,正在推进虚拟国际从“看起来实在”向“动起来实在”的突变。
空间智能敞开无尽想想象力
从技能演进视点看,空间智能代表了人工智能范畴的一种簇新思想办法。它经过将感知信息转换为关于外部环境的笼统模型,使得智能体能够有用猜测和了解周围国际的动态改变。
以自动驾驭为例,空间智能不只能够协助辅佐智驾体系依据历史经验猜测其他车辆和行人的行为,还能在特定情况下提早调整行车战略,极大前进行进安全性与功率。这种依据物理规矩和知识的数字国际生成才能,是以往任何人工智能技能都无法比拟的。
空间智能能够被视为人工智能从“自发感知”走向“自主认知”的跨进,其让人工智能技能开端打破信息空间的限制,向实在国际的三维空间扩展,进一步前进了人工智能在实践环境中的习惯才能。
它不只是人工智能技能的再次进化,更是人工智能体系朝着实在了解和交互咱们所日子的三维国际迈出的要害一步。正如言语智能让人工智能能够了解和生成人类言语相同,空间智能将使人工智能能够了解和操作物理国际。
相较于传统的图画辨认技能,空间智能要求人工智能具有三维空间的了解与实时行为调整才能。经过对动态场景的剖析与决议计划,人工智能不只能够辨认物体,还能够了解它们之间的相对方位和运动轨道。
比方,在杂乱的城市交通环境中,辅佐驾驭体系有必要使用空灰色情侣摆件寓意好吗间智能来猜测交通活动,一起保证能够有用应对突发的交通情况。此种两层才能的结合,让自动驾驭的安全性和可靠性将产生质的腾跃。
空间智能不只拓宽了人工智能的使用场景,也推进了算法的进一步开展。未来,空间智能将为智能体供给更高层次的认知与推理才能,使其能够在仿照的虚拟环境中进行重复试验,然后优化决议计划在实践国际中的使用。
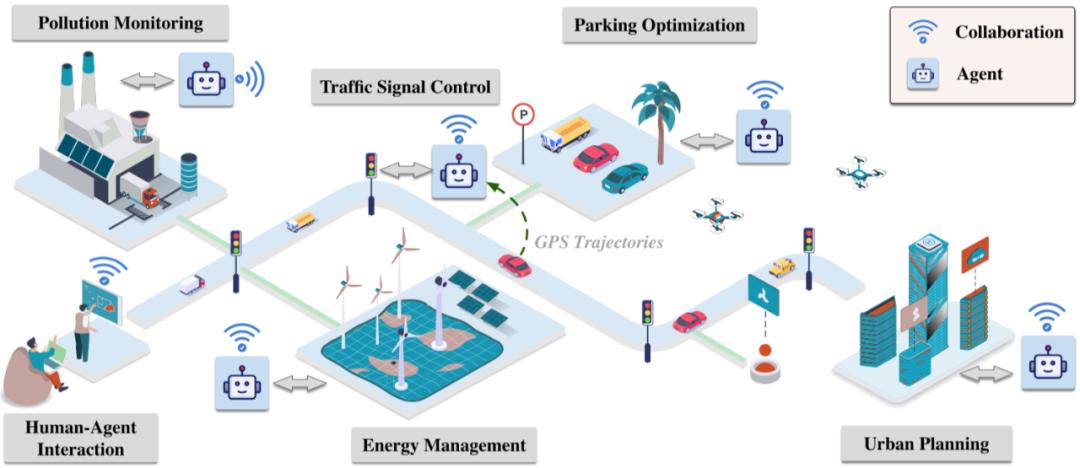
如此,科学家和工程师们能够在无危险的条件下,测验和改善智能算法的体现。这种在虚拟环境中的练习,为实践中的使用供给了愈加稳妥的保证,关于推进技能的老练具有重要意义。
在日本,空间智能已全面铺开。比方日本正在把整个东京进行3D数字孪生化,这是完结AI空间智能的要害一步。这一数字孪生模型的规划十分大,并且它对东京的描写也十分之精密,其肯定方位精度大约在10cm以内,不只包括了LiDAR点云,还有详实的CityGML和实时交通数据。依据日本的预期,到2030年将完结一个完好的数字孪生城市,从交通到动力做到信息无缝交融,越来越多的城市房子、工厂将转化为仿照数据。
关于城市进行的数字孪生其实也便是依据感知的城市数据,在网络空间上像“孪生”相同再现修建物、路途等根底设施与经济活动、人流等各种要素。也便是说,能够经过依据从物理空间各个范畴的活动中获取的实时数据,在网络空间中进行高档剖析和仿照,并将其成果以交互式的方式高速反应到物理空间。
正如英伟达高档研讨科学家Jim Fan所言,未来的城市管理将依赖于实时图形引擎中的仿照和集群体系,这将使得机器人和自动化设备能够快速习惯杂乱的环境。机器人将不会孤登时进行练习,它们能够在实时图形引擎中进行仿照,并经过一个巨大的集群进行扩展,以生成下一个数万亿等级的高质量练习数据。
经过在高精度仿照环境中练习,机器人能取得丰厚的练习数据,并在杂乱场景中快速学习。这种办法将推进机器人从虚拟国际到实践国际的顺畅搬迁,前进其在实践使用中的功率和智能。
与传统的城市仿照比较,数字孪生能够供给实时反应,并跟着城市的动态改变而调整其情况,这使得城市管理变得愈加灵敏和高效。
例如,在新南威尔士州,经过数字孪生和人工智能结合的技能,交通管理能够实时调整以削减拥堵,然后最大程度地前进社会效益。
在我国,物理国际AI大模型MogoMind经过通感算一体化设备整合车辆轨道、交通流量等异构数据,依托交通数据流实时大局感知、物理信息实时认知了解、通行才能实时推理核算、最优途径实时自主规划、交通环境实时数字孪生,以及路途危险实时预警提示六大要害才能,不只能够辨认路面情况、交通标识、障碍物的物理情况,还能将杂乱的交通环境信息转化为可了解、可执行的智能决议计划主张,为交通管理部门和出行者供给应对计划。推进城市交通从“单点智能”走向“大局智能”。
在医疗范畴,空间智能技能能够对医学印象数据进行三维重建和剖析,协助医师更精确地确诊疾病。例如,对CT、MRI等印象数据进行三维重建,能够更明晰地显现人体器官和病变的方位、形状和巨细,为医师供给更精确的确诊信息。一起,空间智能技能还能够为医师供给手术导航和辅佐决议计划,经过对患者的身体结构进行三维建模和剖析,医师能够更好地了解手术部位的解剖结构和血管散布,前进手术的精确性和安全性。
五亿年前,视觉的呈现推翻了漆黑的国际,引发了最深入的动物进化形式。曩昔十年,人工智能的前进相同令人惊叹。当咱们开端为核算机和机器人赋予空间智能,就像大天然敞开了生物多样化年代,人工智能的未来将由此更具无尽想象力。
本文来自微信大众号“极智GeeTech”,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

