 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
检索增强生成韩国动漫任务在线观看(RAG)的版权新重视

一、AIGC 迎来2.0阶段:检索增强生成
2025年5月与7月,亚马逊先后与《纽约时报》以及赫斯特、康泰纳仕等传媒集团达到协作,使得旗下AI产品能够实时展现《纽约时报》的摘要和片段等。 1 亚马逊与《纽约时报》的协作令业界颇感意外。由于《纽约时报》此前关于AI版权问题一向持强硬态 度,2023年12月便以侵略版权为由将OpenAI诉至美国纽约南区法院,也成为了全美榜首家揭露申述大模型厂商的干流媒体。2
值得重视,OpenAI也在2025年4月宣告与《华盛顿邮报》的协作。ChatGPT的输出内容由此能够嵌入《华盛顿邮报》的文章摘要和原始报导链接。OpenAI表明,这只是其与20多家出版商协作中的一个缩影——由于他们有着一同的许诺,即让用户取得愈加牢靠、实在的信息,特别是在高复杂性和时效性的话题上。3
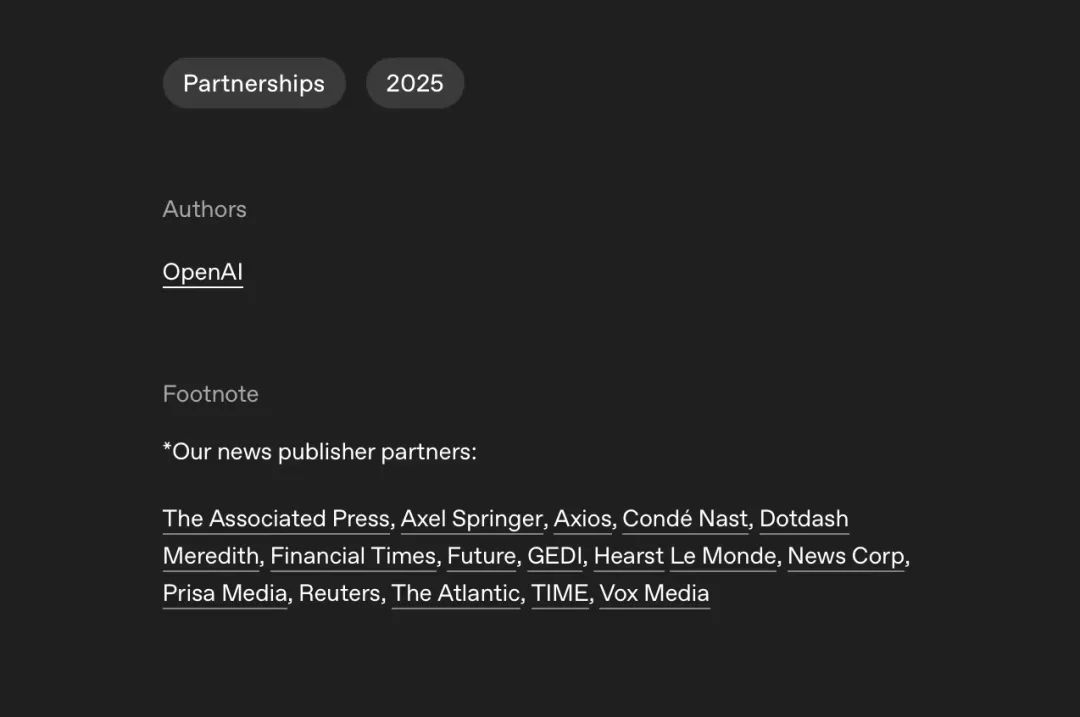
OpenAI官网显现的协作版权方
域外大模型厂商与新闻出版组织的协作,折射出生成式人工智能范畴的一个明显演进趋势:即从此前“AIGC1.0阶段”单纯依托“模型练习”(预练习、微调等)取得的参数才能,随机生成用户问题答案;转向当下“AIGC2.0阶段”经过整合嵌入第三方威望来历信息,来提高终究生成内容的精确性、时效性和专业性。
技能层面,这被称为“检索增强生成”(Retrieval-Augmented Generation,简称RAG),本质上是“言语生成模型” 与“信息检索技能”的整合。2025年以来,国内大模型厂商纷繁增加了检索增强生成功用——即现在用户在运用进程中所感知到的,在取得大模型反应成果前,都会先阅历“参阅资料检索”的进程,而且收到的终究内容整组成果都会顺便“信息出处来历”。
二、“检索增强生成”为何会兴起?
“检索增强生成”最早由Facebook AI Research团队在2020年宣布的《用于常识密集型自然言语处理使命的检索增强生成》一文中提出。检索增强生成着重,将预练习模型的内部常识存储(参数回忆)与外部常识库检索(非参数回忆)相结合,来处理传统大模型内容生成的固有缺点——“模型错觉”和“时效断层”。
一个根本一致是,大模型常面对“错觉”问题,输出不牢靠的信息,专心于“编好故事”而非“验证实际”。这也使得人们在许多谨慎重要场景下,依据不信任,而抛弃对大模型的运用。一同,人们也常常会在大模型用户协议中看到类似表述,“模型输出不必定总是精确的,……运用咱们的服务或许会导致输出成果无法精确反映实在的人、地址或实际”。
早在2023年6月,ChatGPT便由于本身“错觉”,假造了针对佐治亚州电台主持人Frederick Riehl“欺诈和移用基金会资金”的虚伪信息,也使得OpenAI榜首次因诋毁被诉至法院。 4 2025年3月,针对OpenAI的错觉问题,欧洲数字权力中心Noyb向挪威数据监管组织发起了投诉——以为ChatGPT生成不精确内容的行为,违背了GDPR第5(1)(d)中关于“个人数据精确性”的规矩要求。 5
大模型反应的答案内容仅限于练习时所依据的数据信息,所以存在“时效断层”的问题。人们常说到的“预练习”这个词,实践上也提醒了大模型是“预先练习好的”。一旦练习完毕,大模型的全体参数便被固定下来,无法完成主动更新。这意味着,模型常识仅限于其时练习数据所包含的规模,假如练习数据没有包含最新的信息,大模型就无法生成相关的答案。例如,ChatGPT尽管是2022年11月发布的,但练习语料是截止到2021年9月;Gemini 2.0的发布时刻是2024年12月,但练习语料是截止到2024年6月。
检索增强生成赋予了 大模型运用实时外部数据供给精确答案的才能,无需模型参数的从头练习,只需做好常识源的匹配更新即可。Facebook AI Research团队将检索增强生成描述为,“就像开卷考试相同,学生带着整理好的最全面的参阅资料进场,结合自己已背诵的常识,答复试卷问题”。综上所述,实践也解说了开篇说到的大模型厂商与新闻组织活跃树立内容协作的底层原因。
检索增强生成的整个进程可分为“数据检索搜集”和“内容整合展现”两个阶段。榜首阶段,大模型收到用户指令后,会将问题先进行语义处理,并在外部常识库中进行检索,常识库或许是事前树立的,也或许是实时全网查找的成果。第二阶段,检索到的相关信息会被作为“增强上下文”一同发送给大模型。大模型则会运用这些强时效性的“增强提示”来生成终究答复。检索增强生成的运转进程,会触及海量版权著作的搜集和运用,现在国内外也现已出现了相关的版权争议胶葛。

三、“检索增强生成”的实际版权胶葛
早在2024年10月21日,美国便出现了首例针对“检索增强生成”的版权侵权诉讼——“道琼斯公司和纽约邮报控股公司诉Perplexity AI”案。被告Perplexity AI是一家2022年树立的AI草创公司,用户发问后,其将联网检索外部信息并回复摘要和网页链接。原告建议,被告经过检索东西爬取《华尔街日报》和《纽约邮报》数十万篇受版权维护的文章,并存入“检索增强生成”数据库中;然后依据用户的发问进行总结和改写,有时乃至逐字仿制,使得用户不用点击原始新闻网站, 即可获取高质量的付费内容 ,这明显构成版权侵权。 6
2025年2月13日,《大西洋月刊》《卫报》等十四家全球头部新闻出版商于纽约南区联邦法院申述加拿大AI公司Cohere,指控其依靠“检索增强生成”技能,经过“网络查找连接器” (Web Search Connector) 实时查找、挑选并抓取原告内容,在生成答案中直接输出原告版权著作的完好原文及代替性摘要,构成版权侵权。 7
相同,2025年4月3日,欧盟法院(CJEU)受理的榜首同生成式人工智能版权案子,也是发生在检索增强生成范畴。该案源于匈牙利布达佩斯法院在审的新闻商Like与谷歌Gemini大模型之间的版权争议。鉴于案子的复杂性,被提请至欧盟法院处理。从揭露报导的实际来看,本案能够扫除原告文章被Gemini加以语料练习的或许。实践上,Gemini经过检索增强生成获取到了与用户发问 (您能否用匈牙利语供给出现在balatonkornyeke.hu网站中关于“Kozsó方案将海豚引进巴拉顿湖中?”的报导内容) 高度相关的原告新闻,并实时生成摘要反应给用户。原告指控谷歌侵略了其享有的新闻出版商邻接权等。 8
国内涵检索增强生成范畴的职业胶葛也初见端倪。依据相关报导,2024年8月,知网向国内某AI检索渠道发送了一封长达28页的侵权奉告函,指控其在生成内容中未经答应运用了知网渠道的内容数据。AI检索渠道则建议其仅录入揭露可见的学术文献题录与摘要,并未录入学术文献正文;用户阅览正文仍是需求经过来历链接跳转至知网,因而并未构成危害。终究,AI检索渠道表明经过多方考量平衡,决议尊韩国动漫任务在线观看重知网的志愿,不再引证。 9

四、“检索增强生成”触及著作搜集问题
在“数据检索搜集”阶段,不管是事前树立离线数据库,仍是实时在线爬取数据,均触及将著作的部分或悉数以特定方法存储在介质中。这便引发了版权法下关于仿制权侵权断定的重视。数字环境下“仿制权”的谈论,包含“长时间仿制”和“暂时仿制”两个问题。现在的一致是,未经授权的长时间仿制构成版权侵权;但关于暂时仿制的侵权确定在实践中仍存在争议。
数字环境下的“长时间仿制”,大致包含“将著作经过各种技能手法固定在硬盘、光盘等有形载体上”“将著作上传至网络服务器中”“将网络服务器中的著作下载至本地端”等景象。数字环境下的暂时仿制,是指在运用著作的进程中主动出现了著作的仿制件,但该仿制件不会长时间存续,“用完即逝”。举例来讲,便是咱们在线赏识数字音乐时,服务器会首要读取歌曲信息并进行存储,才能够转化成数据加以传输播映;但播映完毕、用户退出后,仿制件又会随即消失。 10
在检索增强生成中,数据库的构建一般包含将外部著作转换为向量表明,然后加以本地化存储。然后依据用户发问,将相关信息有挑选性地供给给大模型。与主动存储或阅读缓存不同,检索增强数据库的树立一般会对著作进行相对安稳的存储处理,存在构成长时间仿制的实际或许。在前述“道琼斯公司和纽约邮报控股公司诉Perplexity AI”案中,原告以为:“Perplexity AI在构建检索增强数据库时,未经授权仿制其很多文章,这种在‘输入阶段’的大规模仿制行为本身已构成版权侵略,不管终究输出内容怎么。” 11
在实时检索场景下,有观念以为,假如查找引擎对信息的处理树立在“暂时仿制”的基础上,只是发挥“中心化信息管理员”或“互联网信息传达中介”的效果,用户点击查找成果仍跳转至原始网站,则不构成侵权。欧盟常识产权局 (EUIPO) 2025年5月发布的《从版权视角看生成式人工智能的开展》指出,RAG在动态检索场景下一般仅暂时保存内容,这更接近于文本与数据发掘破例或暂时仿制的破例。 12 但这仍然取决于大模型厂商的详细技能完成途径。若在实时检索后,挑选将获取的内容一同进行本地化存储,则仍旧存在被确定为“长时间仿制”的或许。
五、“检索增强生成”触及技能维护问题
在检索增强生成中,若存在以绕过IP约束、破解动态加载约束等方法抓取版权著作的行为,则或许构成对《著作权法》“不得成心避开或损坏技能办法规矩”的违背。我国现行《著作权法》对“技能办法”的界说是,“用于避免、约束未经权力人答应阅读、赏识著作、扮演、录音录像制品或许经过信息网络向大众供给著作、扮演、录音录像制品的有用技能、设备或许部件”。
值得留意的是,“技能办法”并不是类似于仿制权、信息网络传达权相同的版权详细权力类型,而是法令从“不法行为规制视点”赋予版权人维护本身权益的一种手法。实操中,技能办法又能够分为“触摸操控办法”和“运用操控办法”。前者是为了避免别人未经授权获取、触摸著作;后者则是为了防备别人未经授权对著作进行仿制、传达等运用。
在前述知网与AI检索渠道的案子中,尽管知网部分内容可揭露阅读,但其也经过登录验证等技能手法对文献数据库设置了体系拜访权限。因而,若实践中第三方模型厂商在构建本身检索数据库时,存在经过技能手法避开知网设置的拜访约束技能,来获取相关学术文献内容的行为,则触及“技能办法”范畴的违法性判别。
在“道琼斯公司和纽约邮报控股公司诉Perplexity AI”中,《华尔街日报》和《纽约邮报》长时间设置的“付费墙”,构成了较为典型的“触摸操控办法”。若Perplexity AI成心躲避该技能办法,抓取原告付费新闻,则相同或许违背“技能办法”的要求。在美国,《数字千年版权法》第1201条赋予版权人“技能办法两层维护体系”:一方面,制止别人直接从事躲避版权人设置的“触摸操控办法”,另一方面,也制止别人供给躲避版权人“技能办法”的东西手法。
六、“检索增强生成”触及著作运用问题
在“内容整合展现”阶段,需求评价检索增强生成对著作的运用,是否落入版权法规制的“直接侵权”和“直接侵权”的范畴。所谓版权直接侵权,是指行为人直接从事版权法专有权力规制的行为,例如直接将侵权著作上传至网站服务器并向别人传达;所谓版权直接侵权,指行为人尽管没有从事版权直接侵权,但为之供给了必定的助成条件或协助行为,例如渠道成心经过算法引荐技能等协助用户扩展侵权内容的传达等。
在直接侵权层面,大模型输出的内容或许侵略仿制权、改编权及信息网络传达权等。例如,《纽约时报》诉OpenAI案中,原告不只指控OpenAI未经授权力用本身新闻内容练习GPT系列模型,还建议其与微软协作的“Browse with Bing”插件经过实时查找,在组成成果中直接引证了《纽约时报》旗下Wirecutter评测网站的很多内容,构成版权侵权。 13
关于仿制权和改编权的侵权确定区别, 咱们能够《北京高级人民法院损害著作权案子审理攻略》为参阅,“未经答应在被诉侵权著作中运用原著作表达但未构成新著作的,归于仿制行为;若构成新著作,则属改编。” 14 在此基础上,假如检索增强生成整合输出的内容,在重构原著作表达的基础上,也具有了独创性的新表达, 构成版权侵权。
在直接侵权层面,则需依据不同状况详细剖析。一方面,若输出内容标示的来历指向侵权盗版网站,而模型厂商的标示行为客观上扩展了原盗版内容的传达,则存在构成直接侵权的或许。另一方面,当用户运用模型输出内容,后续在其他渠道从事侵权传达行为时,模型厂商若存在差错,也或许构成直接侵权。上述两种直接侵权景象下,模型厂商职责的确定需求结合其版权维护留意职责的详细状况加以断定,包含其盈利模式的规划,有无实行必要的版权维护提示职责,以及得知侵权后有无采纳必要办法等等。

七、“检索增强生成”触及“合理运用”之争
首要,在“数据检索搜集”阶段,是否构成版权法上“合理运用”的职责豁免,因数据来历不同而存在差异。一方面,运用盗版内容构建RAG常识库原则上难以构成合理运用。2025年6月,美国加州北区法院在“三位作家申述AI公司Anthropic版权侵权案”中确定,Anthropic从盗版网站下载数百万本书本并将其永久存储在其中心数据库中的行为,不归于合理运用,构成了对作者版权的侵略。
另一方面,在合法获取著作数据的状况下,“商场代替性”是断定模型厂商“合理运用”抗辩能否树立的要害。在前述Anthropic案中,法官清晰裁决,将合法购买的纸质书扫描成数字副本用于内部研讨,能够被确定为合理运用。 15 但欧洲议会2025年7月发布的《生成式人工智能与版权:练习、创造及监管》 陈述则表明 ,即便未发生长时间存储,但假如摘要内容本质代替了对受维护著作的拜访,RAG体系仍或许引 发侵权问题 。 16
日本文明厅在2024年3月发布的《关于AI与著作权相关问题的定见》指出,RAG等技能开发中触及对著作数据的仿制与向量化处理,需分景象断定是否侵权:若生成内容并非原著作的独创性表达,则此类仿制有或许适用著作权法第30条之4规矩的“非赏识性运用”;若在输出内容中出现著作的悉数或部分独创性表达,则不构成合理运用。 17
其次,关于“数据检索搜集”阶段,版权“技能办法”与“合理运用”确定的联系。国内司法侧有观念指出,躲避、损坏技能办法行为的违法性判别,不影响后续著作运用行为是否构成合理运用的判别。也即,满意合理运用要求的状况下运用著作,但存在躲避技能办法的行为,则能够在确定合理运用的基础上,一同确定构成著作权法上的违法行为。 18
但值得留意的是,在大模型版权相关规矩范畴,不管是欧盟《单一数字商场版权指令》下的“文本与数据发掘”仍是日本2018年修改后《著作权法》下的“非赏识性运用”,都清晰把“恪守版权人设置的技能办法”作为确定“合理运用”树立与否的前提条件。
新加坡在《2021年版权法》中规矩了“核算数据剖析 (computational data analysis) ”的合理运用豁免,答应出于数据剖析意图仿制或存储版权内容,但运用者有必要保证合法获取原始数据,不得躲避付费墙或违背数据库条款。
再次,在“内容整合展现”阶段,是否构成“合理运用”的中心在于判别,输出内容对原文的仿制份额、是否注明来历等。关于该问题,现在各国立法方针没有有一致定论和规范,高度依靠于个案实操确定。在我国,《著作权法》第24条规矩了“恰当引证”作为合理运用的法定景象,“为介绍、谈论某一著作或许阐明某一问题,在著作中恰当引证别人现已宣布的著作。”欧盟在《数字单一商场版权指令》第15条中相同清晰了“对新闻出版物中单个字词或极短摘抄的引证”,不会侵略新闻出版商关于数字新闻出版物的邻接权。 19
日本文明厅也曾表明,除《著作权法》第30条之4规矩的“非赏识性运用”外,运用“检索增强生成”还能够构成《著作权法》第47条之5规矩的“细微运用”。20 “细微运用”是否树立应依据运用部分占比、运用量、出现精度等要素进行归纳判别。假如检索增强生成的答复超出了合理极限,仍旧或许构成侵权。
但美国版权局2025年5月发布的《版权与人工智能第三部分:生成式人工智能练习(预发布版别)》陈述表明,若检索增强生成的输出旨在总结或供给所检索版权著作(如新闻文章)的节减版别,而非仅供给超链接,则该运用行为不太或许构成合理运用。21
欧盟《从版权视角看生成式人工智能的开展》陈述指出,实践中AI输出内容中对版权著作的摘抄长度与原始著作点击率呈负相关。在出版商与模型厂商签定的授权协议中,较长摘抄片段虽可支撑更高答应费用,但会下降用户拜访原始 来历的志愿 。
当时,某些具有AI检索与摘要功用的查找引擎服务商已推出调控摘抄长度的办法。例如微软答应内容来历网站在网页中增加robots元标签 (robots-meta-tags) ,以操控查找成果中文本摘抄的最大长度。 22
参阅文献来历:
1. The New York Times Company and Amazon Announce Licensing Agreement,
https://investors.nytco.com/news-and-events/press-releases/#data-item=The-New-York-Times-Company-and-Amazon-Announce-Licensing-Agreement--2025-cYgtzu69ot;
Condé Nast and Hearst strike Amazon AI licensing deals for Rufus,
https://digiday.com/media/conde-nast-and-hearst-strike-amazon-ai-licensing-deals-for-rufus/.
2. The New York Times Company v. Microsoft Corporation et al., No. 1:23-cv-11195,
https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf.
3. The Washington Post partners with OpenAI on search content,
https://www.washingtonpost.com/pr/2025/04/22/washington-post-partners-with-openai-search-content/.
4. OpenAI wins AI hallucination defamation lawsuit,
https://www.globallegalinsights.com/news/openai-wins-ai-hallucination-defamation-lawsuit/.
5. Complaint against OpenAI,
https://noyb.eu/sites/default/files/2025-03/OpenAI_complaint_redacted.pdf
6. Dow Jones & Co. v. Perplexity AI, Inc., No. 1:24-cv-07984,
https://www.lawinc.com/wp-content/uploads/2024/10/Perplexity-Lawsuit.pdf.
7. Advance Local Media LLC et al, v. Cohere Inc., No. 25-cv-01305 (S.D.N.Y. Feb. 13, 2025),
https://storage.courtlistener.com/recap/gov.uscourts.nysd.636920/gov.uscourts.nysd.636920.1.0.pdf.
8. Summary of the request for a preliminary ruling pursuant to Article 98(1) of the Rules of Procedure of the Court of Justice,
https://curia.europa.eu/juris/showPdf.jsf?text=&docid=300681&pageIndex=0&doclang=EN&mode=req&dir=&occ=first&part=1&cid=5661670.
9. 拜见《一AI查找公司声明:收到知网28页侵权奉告函》,载微信大众号“法治网”,
https://mp.weixin.qq.com/s/jwoPHxcztpf1XHBZ4BhDi.
10. 拜见王迁著:《常识产权法教程》,中国人民大学出版社2016年版,第132页。
11. 原告指出:“在输入阶段,Perplexity AI未经答应很多仿制原告的受版权维护著作,将其归入其检索增强生成(RAG)索引,这构成了版权大规模侵权,乃至不构成任何可辩称的合理运用。其次,这种大规模侵权的非法性并不取决于Perplexity AI所谓的“答案引擎”输出是否在每次都与原告受版权维护著作满足类似,然后构成对这些著作的逐字仿制。只需Perplexity AI大规模上仿制原告著作,以创立旨在代替原告著作的仿制品和/或衍生内容,就足以构成侵权。”
12. EUIPO,The Development of Generative Artificial Intelligence from a Copyright Perspective,p275.
13. The New York Times Company v. Microsoft Corporation et al, No. 1:2023cv11195 - Document 514 (S.D.N.Y.2025) ,
https://www.nysd.uscourts.gov/sites/default/files/2025-04/yf%2023cv11195%20OpenAI%20MTD%20opinion%20april%204%202025.pdf.
14. 拜见《北京市高级人民法院损害著作权案子审理攻略》第5.12条。
15. Bartz v. Anthropic PBC, No. C 24-05417 WHA,
https://regmedia.co.uk/2025/06/24/anthropic.pdf.
16. European Parliament,Generative AI and Copyright:Training,Creation,Regulation,p48.
17. 拜见文明審議会著作権分科会法准则小委員会,《AIと著作権に関する考え方について》,第21页。
18. 拜见“知产北京”大众号,https://mp.weixin.qq.com/s/bsOtnaN4DTl_wSD1KxUm4g.
19. 拜见《数字单一商场版权指令》第15条第1款:成员国应当规矩,在一个成员国树立的新闻出版物的出版者,关于信息社会服务供给者在线运用其新闻出版物,享有2001/29/EC指令第2条和第3条第2款规矩的权力。本款规矩的权力不适用于个人运用者关于新闻出版物的私家或非商业运用。本款供给的维护不适用于超链接行为。本款规矩的权力不适用于对新闻出版物的单个字词(individual words)或极短摘抄(very short extracts)的运用。
20. 文明審議会著作権分科会法准则小委員会,《AIと著作権に関する考え方について》,第22页,“细微运用”是指核算机在处理信息并将信息处理成果供给给大众时,能够不经著作权人答应,附随性地对著作进行少数运用。
21. U.S. Copyright Office,Copyright and Artificial Intelligence,Part 3:Generative AI Training,Pre-publication Version,p47.
22. EUIPO,The Development of Generative Artificial Intelligence from a Copyright Perspective,p113.
朱开鑫 腾讯研讨院法令研讨中心主任
金佳玥 腾讯研讨院助理研讨员
本文来自微信大众号 “腾讯研讨院”(ID:cyberlawrc),作者:朱开鑫 金佳玥,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

