 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
《纽约时报》们攻击Per撒野小说无删减在线听书plexityAI,“今天头条版权门”再度演出?
要说有什么瓜,能从上一年吃到本年,那有必要得有一大批传统媒体“开撕”AI大厂的一席之地。
为了避免有人还不知道这事儿,我先简略告知下布景。
这次工作的主角是一家在AI圈内声名鹊起、估值已达180亿美元的草创公司——Perplexity AI。
而站在他们对面的,则是一个由全球尖端媒体组成的“复仇者联盟”:日本最大的报业集团《读卖新闻》、英国广播公司(BBC)、新闻集团旗下的道琼斯(《华尔街日报》母公司)和《纽约邮报》,以及早已向其宣布“终究通牒”的《纽约时报》。
这些传统媒体们给Perplexity AI安的罪名是未经答应运用版权资料,他们还在自家网站上发了篇文章,专门报导了这事儿。

(图源:读卖新闻)
乍看之下,这像是一场传统媒体巨子对新式技能公司的围歼,一场“旧时代”对“新物种”的宣战。
但当你深化了解Perplexity的工作方法后,你会发现,这场争斗远比幻想中杂乱。它不只仅是关于几篇文章的版权归属,更是关于互联网信息流通方法、商业方式乃至整个内容生态未来走向的一场深入博弈。
(图源:雷科技制造)
这一幕,与2014年搜狐新闻们联合起来控诉今日头条何其相似。当年,作为新物种的今日头条用“千人千面”的引荐算法推翻了互联网内容分发体系,多家传统媒体以及门户网站对今日头条建议诉讼。

那么这一次媒体们申述Perplexity AI又是怎么回事呢?
AI答案引擎PerplexityAI动了谁的蛋糕?
要了解这场风暴,咱们首要要搞清楚Perplexity究竟是什么。
许多人将其称为AI搜索引擎,但这并不完全精确。与其把它看作下一个谷歌,不如称其为答案引擎。这个定位上的细微差别,正是其推翻性与争议性的本源地点。

(图源:Perplexity)
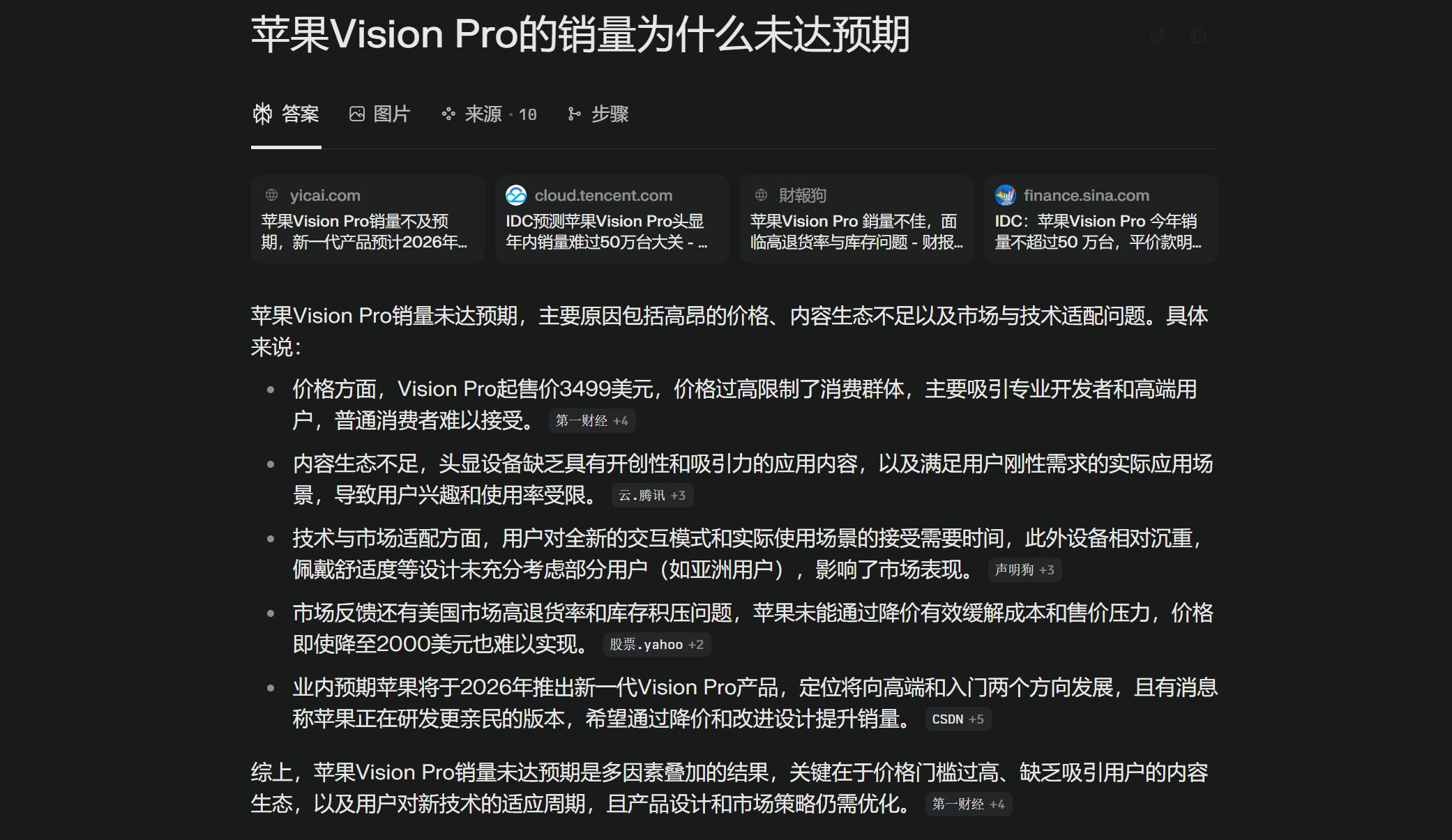
咱们以一个简略的场景为例,假定你想了解“苹果Vision Pro的销量为什么未达预期”,在传统搜索引擎上,你会得到一个长长的链接列表。
你需求像一个侦察相同,逐个点击、阅览、挑选、区分,终究在脑中自己拼凑出答案。此刻谷歌的人物,更像是一个尽职尽责的图书管理员,他告知你相关的书本都在哪些书架上,但找书和看书的功夫,还得你自己来。
它的中心是指路,将流量导向终究的内容源头。
而Perplexity则不同,当你问出相同的问题,它不会给你一堆链接。
(图:雷科技)
相反,它会直接生成一段文字,告知你原因或许包含价格过高、运用生态不完善、佩带舒适度问题等等,并在阶段结尾附上几个信息来历的角标,就像是替你读完了全部的资料,并把消化、提炼后的定论直接喂到你嘴边。
它的中心是回答,将信息价值汇聚在自己的渠道之上。
这种一步到位的便当性,关于用户而言的确是很便当的,它缩短了用户从提出问题到取得答案的途径,供给了史无前例的信息获取功率,这也是现在搜索引擎纷繁融入大模型的原因之一。
可是,这种极致便当的背面,却是对传统互联网生态链的一次降维冲击。
传统新闻网站辛辛苦苦派记者采访、花修正时刻编撰、投入本钱运营换来的深度文章,其最中撒野小说无删减在线听书心的信息价值,被Perplexity的AI模型轻松吸走,然后打包成了自己的产品。

(图:读卖新闻)
这种方式直接损害了出版商们赖以为生的底子:流量、广告展现、付费订阅。在这套新玩法面前,这些都成了为人作嫁的笑话。用户在Perplexity上就现已称心如意,天然也就没有了点击原始链接、拜访新闻网站的需求。
更夸大的是,在此之前,假如你告知Perplexity由于付费没法儿看某篇文章,让它给你打出原文的榜首段,然后再让他给出下文,就能完全绕过付费墙,直接看文章了。

(图:雷科技)
不过我试了一下,现在却是会提示版权约束了,可是要害内容仍然会以摘要的方式进行展现。
更让媒体无法承受的,是他们急进的数据抓取手法。
依据云安全公司Cloudflare的陈述,Perplexity存在绕过网站规矩、抓取受维护内容的行为。当网站的robots.txt协议清晰表明“谢绝爬虫”时,Perplexity的机器人会通过修正自己的署理信息,伪装成一般的浏览器用户,以此蒙混过关。
说实话,看完来龙去脉后,我觉得Perplexity这么做的确有那么点不宽厚。
这也难怪,读卖新闻在终究的诉求里要Perplexity补偿21.68亿日元(约合1.06亿元人民币)的丢失。
内容源头“说不清”成了大模型的“原罪”
风趣的是,Perplexity现在所面临的攻击,并非孤例。
事实上,放眼整个AI职业,相似的争议早已层出不穷,简直成了全部AI巨子都无法绕开的“原罪”。
这片烽火,早现已从新闻业蔓延至文学、艺术乃至软件编程的每一个旮旯。
在文本范畴,2023年底,《纽约时报》正式对OpenAI提申述讼,指控其不合法运用数百万篇文章来练习ChatGPT。诉状中最丧命的依据,莫过于展现了ChatGPT在特定提示下,能够简直逐字逐句地复述自家的付费版权内容。

(图源:US GOV)
紧随其后的,是一个由很多闻名作家组成的“复仇者联盟”,包含《权利的游戏》作者乔治·R·R·马丁在内的美国作家协会一起建议团体诉讼,控诉自己一生的汗水之作,在未经答应、未获分文酬劳的状况下,沦为了大模型“坐收渔利”的练习资料。
在图画范畴,抵触相同白热化。全球最大的图库Getty Images在诉讼中宣称,Stability AI不合法抓取了其超越1200万张图片进行练习,部分生成的图画中,乃至还能看到Getty Images那标志的躲藏水印。
此伏彼起的争议,指向了当时生成式AI开展的两个底子性问题。
首要,是模型对大规模练习数据的需求。 要让一个AI变得更智能,开发者就有必要为其投喂更大的数据集,这种对数据的需求,决议了AI公司必然会选用“地毯式”的扫荡战略,将互联网上全部可及的数据都归入囊中。
其次,是AI公司企图重塑互联网生态的野心。Perplexity不只要做网页、插件,更是最近推出了Comet浏览器,旨在成为新的“互联网进口”,撒野小说无删减在线听书期望用答案完全代替传统的网页链接。
这种商业方式的实质,便是流量截留,能够说直接动摇了整个内容工业的根基。

(图源:Perplexity)
面临翻天覆地而来的诉讼,Perplexity表明自己底子就不是做AI大模型的,企图以自己仅仅一个署理运用为由撇责,他们以为抓取网页信息的机器人应该被视为用户驱动的AI帮手,但这并不能解说为什么他们能够不经答应直接输出别家网站的内容。
至于那些在练习大模型的AI公司们,则不谋而合地举起了一面法令大旗——合理运用,他们宣称,运用受版权著作练习AI就像一个学生为了学习写作而博学多才,其意图在于技能创新,而非商场代替,当时呈现原文的状况仅仅BUG罢了。
要我说,这种说法多少也有点甩锅的意思。
内容版权问题成AI工业的要害之殇
你还甭说,这次工作的重视度还蛮高的。
一边是老牌传统媒体,一边是新式AI巨子,工作发生后,马上就有人把这次的案子,拔到了AI版权胶葛里程碑的高度。

(图源:X)
乃至,还有不少科技、媒体圈的大佬亲身下场站队,可是一向到现在,也没人能说得清楚究竟谁对谁错。
给一众吃瓜大众,看得是一愣一愣的。
风趣的是,虽然官司打得震天响,但到现在,还没有任何一家大型AI公司,由于在练习数据方面的版权争议而被法庭终究裁决需求付出巨额补偿。
这是由于,在法庭之外,一种默契正在悄然构成。为了躲避法令危险,许多AI公司都开端挑选花钱买安全,自动与内容出版商达到授权协议,OpenAI、苹果等巨子,更是已在活跃寻求与各大媒体的内容协作。

(图源:Axios)
这提醒了一个略显严酷但有必要供认的实际——
一方面,咱们无法否定AI公司在开展初期存在着对版权的无视,其带来的利益胶葛是实在且深入的;另一方面,咱们也不得不供认,没有海量的数据滋补,就没有今日咱们所见到的、能够极大提高生产力的强壮AI。
持续停留在偷与抓的混乱状态,对两边都是一种耗费,或许是时分跳出二元敌对,树立一个规范化的、掩盖全职业的数据运用和同享机制了。
依雷科技之见,这个机制完全能够学习音乐工业的版税体系。
这样AI公司不再需求鬼鬼祟祟地去抓取数据,而是能够通过向这个安排付出答应费用,合法地获取高质量、通过授权的练习数据,而该安排则依据数据被运用的频率等目标,将收入分配给作为内容源头的媒体、作家和艺术家们。
如此一来,AI的开展便有了合法、安稳、高质量的资料,而内容创作者们的辛勤劳动也能取得应有的报答,然后促进良性循环。
本文来自微信大众号“雷科技”,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

