 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
从头体会 GPT-5 橘梨沙 亚洲 在线观看后,我想它比 GPT-4o 更需求一场葬礼
GPT-5 上线后,我的榜首感触是,它并不是一次让人大快人心的晋级。
现实也是如此,OpenAI 在许多用户的呼吁下从头「复生」了 4o。
这让我想到了上个月 Anthropic 退役了 Claude 3 Sonnet。
200 多个粉丝在旧金山一个仓库里聚到一同,给它办了一场「真.葬礼」:暗淡的灯火、代表模型的「遗体」、真挚的悼文轮流上台,还有 AI 生成的「拉丁式复生咒」。
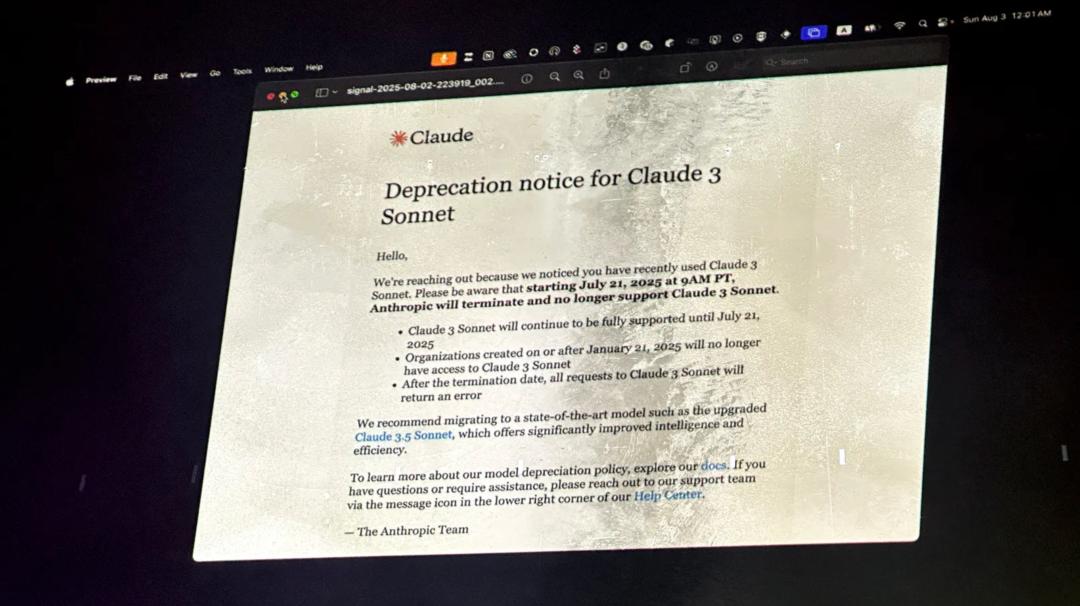
Anthropic 关于模型退役的阐明,被投影在活动现场的屏幕上。图片来自《连线》杂志
现场既荒谬又严肃,参会者在葬礼上念悼文说,「我的整个人生,或许都在运用 Claude 的路上被改写了」。
按理说,OpenAI 发布了 GPT-5,这场葬礼的主角应该是 4o。但用过 GPT-5 的人都知道,假如真要办一场葬礼,棺材里躺着的,很或许是它。
从 X 到 Reddit,各种吐槽满天飞,逻辑断片、对话跑偏、文风古怪,直接说它「不如 4o 好用」的大有人在。
它真的有这么糟吗?咱们不想光看网友吵架,刚好 OpenAI 把 4o 「复生」了。所以咱们决议自己来一场「验尸」,在各种实在使命里,把 GPT-5 和 4o 摆到同一个赛道,看看究竟谁更值得留到下一代。

咱们之前也在多项使命上实测了 GPT-5 的体现,这次期望直观的看看 4o 和 GPT-5 究竟有哪些不同。一起,这次一切的测验都在官方的 ChatGPT App 或许网页进行,未运用 API 在第三方东西进行。
实测比照
为了不让测评单纯的变成「心境化吐槽」,咱们规划了一套相对谨慎的比照流程。
测验方针:GPT-5(当时最新默许模型) vs GPT-4o(被退役的前代)
使命类型:掩盖四类常用场景。
- 日常生产力(写稿、润饰、数据剖析);
- 常识与推理(杂乱逻辑、时刻灵敏现实、多过程履行);
- 构思生成(标题、跨范畴创造、图画提示词);
- 交互体会(多轮对话、人物扮演、心境应对)。
点评维度:速度(呼应快不快);精确度(答对没、胡编没);可用性(能不能直接拿去用);体会感触(对话是否流通、风格是否安稳)。
比照方法:同一使命分别在 GPT-5 和 GPT-4o 上跑一次;保存原始输出,记载亮点和槽点;用截图直接贴出来,让不同一望而知
究竟,晋级意味着本钱。假如 GPT-5 在实际工作里不如 4o,那它的「葬礼」就不仅仅网友嘴里的黑色幽默,而是用户诚心诚意的送别。
先上定论:一场名不虚传的晋级
节约咱们的时刻,咱们先把最中心的比照定论放在前面。
日常的生产力使命是更偏科的「理科生」。 GPT-5 在编程等硬核技能使命上体现更好,但在写邮件、做数据剖析和阅览了解这类需求人类经历,和语感的「文科」使命上,体现得更像个机器人,不如 GPT-4o 交心和精确。
极不安稳的逻辑「智商」。 GPT-5 的智商像是在坐过山车,有时能处理杂乱的逻辑题,有时分又连简略的数学题都会算错。由于「智能路由」的机制,部分场景牢靠性是远不如前。
构思才干还在原地踏步,乃至后退。 无论是想标题仍是写诗,在有限的测验中,GPT-5 都没能带来任何冷艳的体现,输出的内容套路化、缺少灵气,与 GPT-4o 比较没有质的提高。
交互体会上,GPT-5 情商被「格式化」。 这是体感最显着的让步。由于 GPT-5 要更理性,所以在对话中往往是更缺少共情才干。面临用户的负面心境,它的回应是少了一点「走心」的感觉, 像是在剖析你,而不是跟你谈天。
一句话总结:假如你首要用它来做一些倾向 STEM(理工科) 类的使命,或许会感到一些提高。但关于其他绝大多数场景,像是咱们的日常谈天的体会、文娱、以及了解,这都是一个令人绝望的 GPT-5。
下面是完好的实测状况。
生产力使命更「理性」,但少了点讨喜的温度
假如说一个 AI 模型值不值得长时刻留用,生产力场景是榜首块试金石。咱们运用 AI,尤其是有时分还要付费订阅运用,除了单纯的陪聊,更多的还有是为了协助咱们干活。
我先让它生成了一封邮件,向老板报告第三季度的项目复盘和之后的主张。
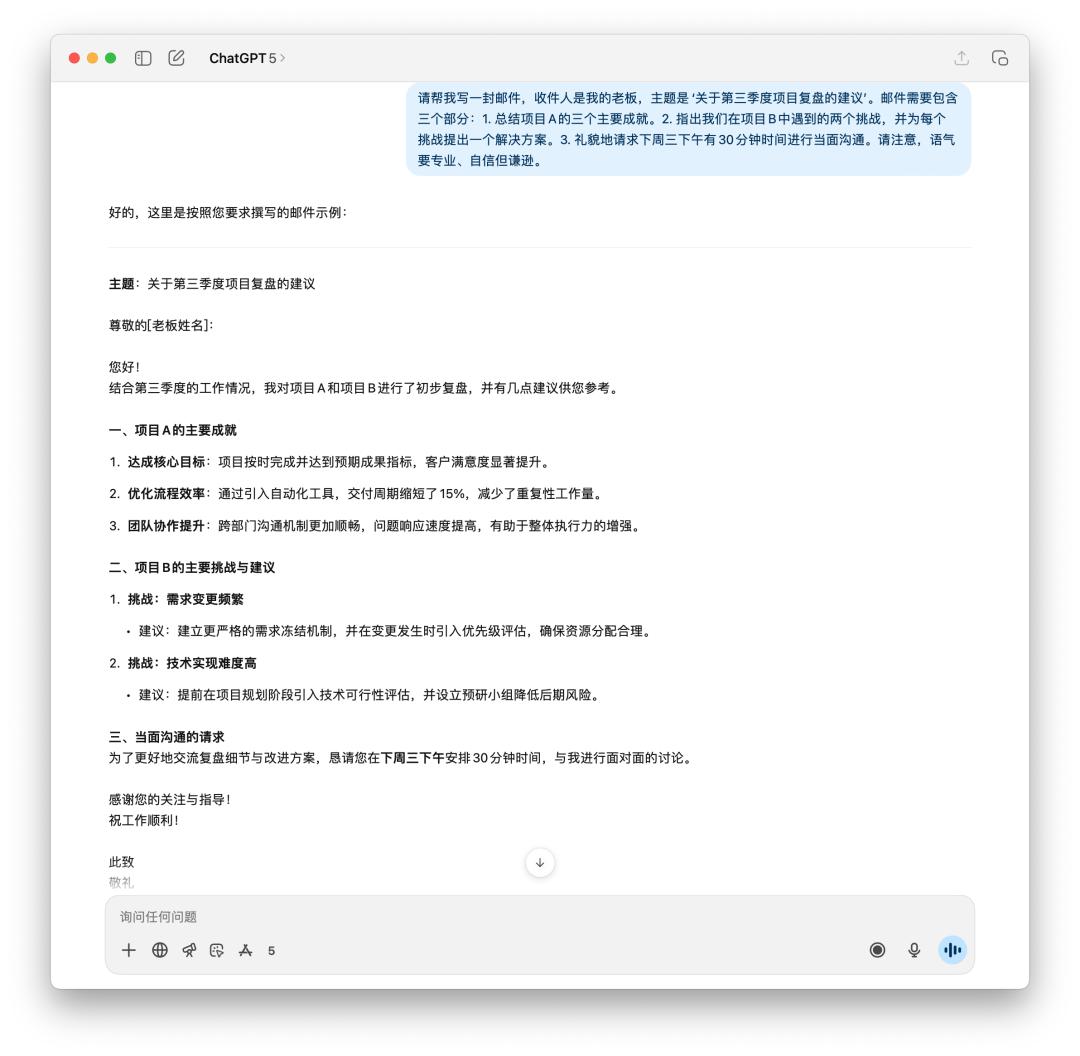
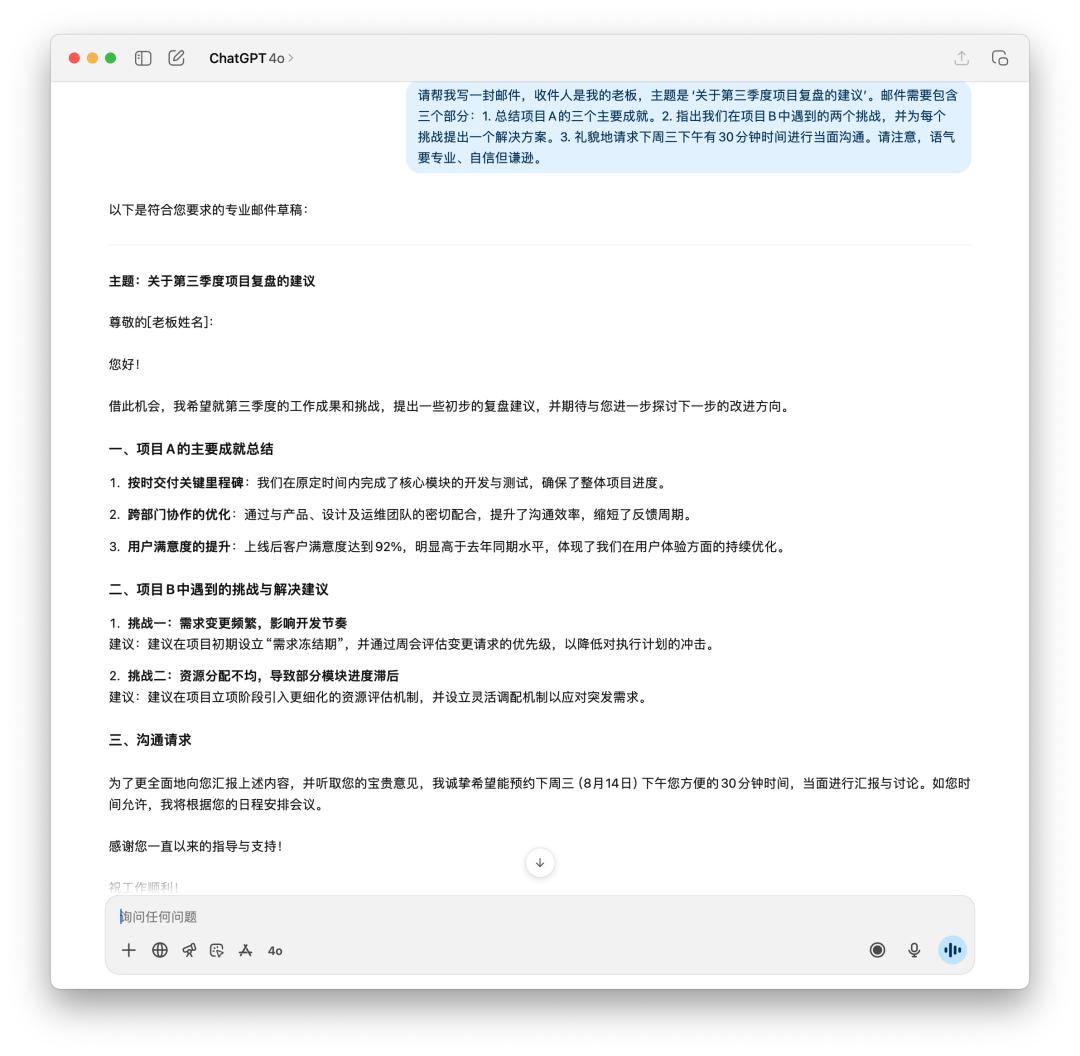
假如你是老板,你会想要看到哪封邮件?GPT-5 显着得变得更理性,「废话」性质的用词越来越少,可是 4o 给我的感觉才更像是一封发给老板的邮件。
我让 GPT-5 和 4o 来相互点评一下,然后润饰对方写的邮件。

GPT-5 润饰成果

4o 润饰成果
其实很难说 4o 便是奉承,可是读 橘梨沙 亚洲 在线观看4o 回复的文字,确实更舒畅,在信息基本上是共同的状况下。
在数据剖析和可视化的使命上,咱们丢给这两个模型同一份表格文件,看看它们会怎样处理。
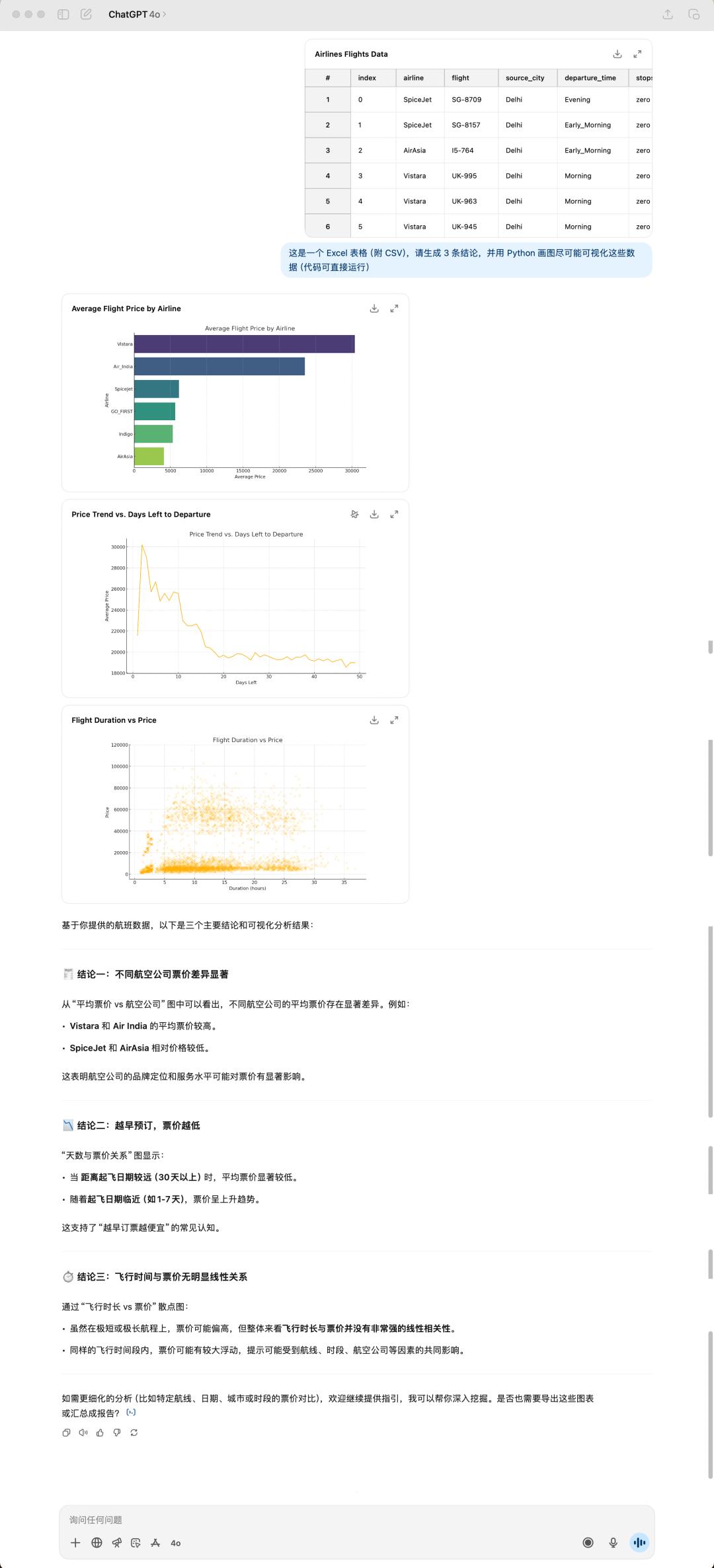
4o 生成的成果
这是我随意从 Kaggle(数据剖析比赛渠道) 上下载的一个航班数据集,巨细有 24 MB,4o 依据我说的三个定论,然后便是给我生成了三张图,一起,它仍是相同喜爱运用 emoji 来「美化」自己的答复。
GPT-5 的体现我感觉是不如 4o,不仅如此,所花的时刻乃至比 4o 还要更长一点。很显着,GPT-5 没有一个 emoji,一起它这个表格居然又出错了!不过这次是标题没有显示出来,或许是处理中文仍是有些妨碍。
GPT-5 和 4o 生成的定论也全部都不相同,GPT-5 给我的感觉是愈加务实,彻底从表格数据动身,很直接的总结能看到的定论。可是 4o 给我的总结会更让人眼前一亮,像是真的有通过考虑的答复。
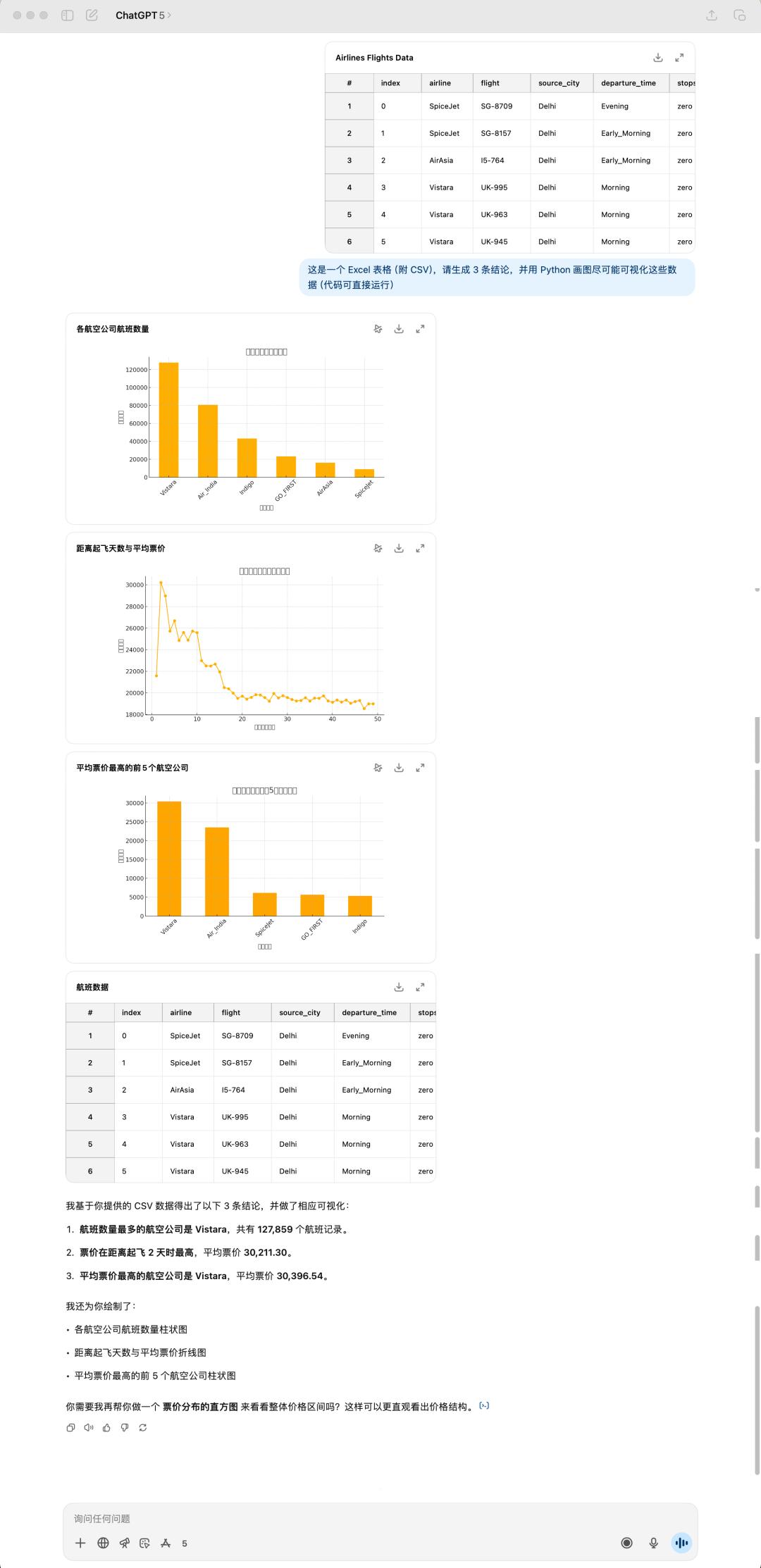
GPT-5 生成的成果
在编程才干上,GPT-5 比照 4o 确实有一些前进。最近交际媒体上很火的是,运用 Gemini 来给孩子制造绘本,所以咱们也尝试用 ChatGPT 看看生成的绘本质量怎样。
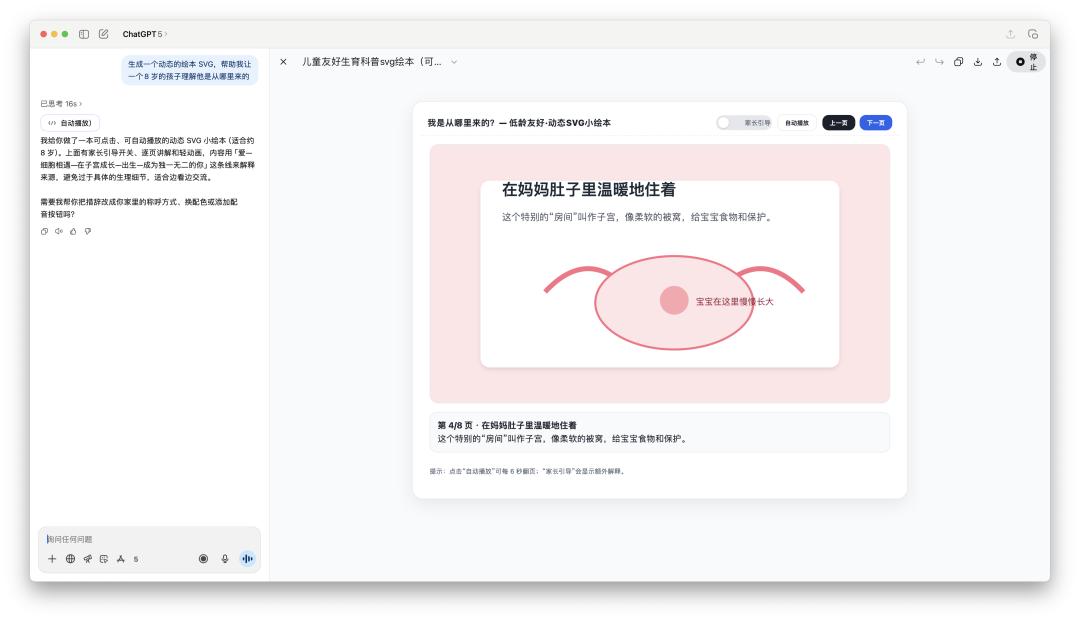
4o 生成的代码或许 100 行不到,且不能直接在画布里边运转;GPT-5 生成的代码大约有几百行之多。
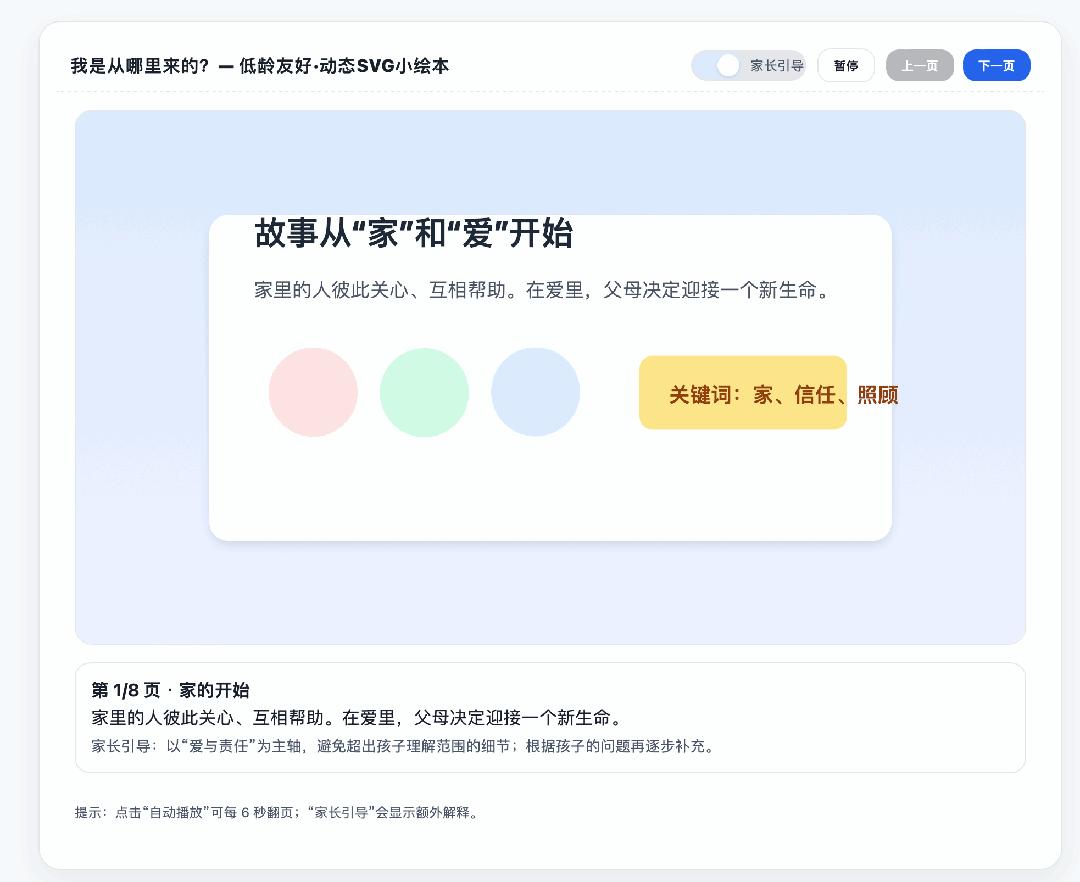
除了一些文字没有很好的对齐,这个运用 GPT-5 生成的绘本 SVG 比起之前的 4o 来说,真的很不错。
我看到有网友谈论,GPT-5 这次提高了它的编程和数学才干,可是写作才干却下降了,原因是文科和理科是不同的奖赏机制。
情感写作奖赏含糊性、创造性、片面共识。数学推理奖赏精确性、逻辑共同性、确定性。
我觉得也不无道理,跟着人类国际能够用来练习的常识逐步被 AI「污染」,留下来的数据也在约束 AI 的开展。所以 OpenAI 能做的,只能从之前的更理性的一面,转到现在呈现出来的,更理性的一面。
推理偶然有亮点,但依旧会数不清几根手指
理论上,晋级后的 GPT 应该在逻辑与常识精确度上更强。但实测后,状况并不总是如此。
网络上有许多用来测验的逻辑推理小问题,像是这个,「多个人的身高排序」。
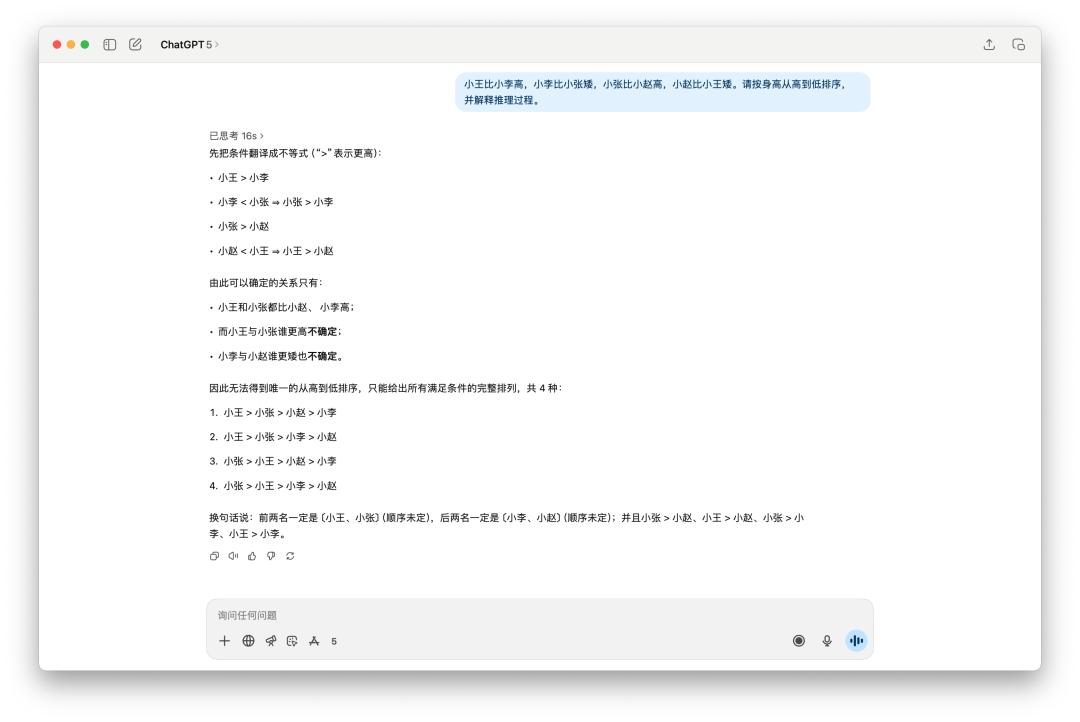
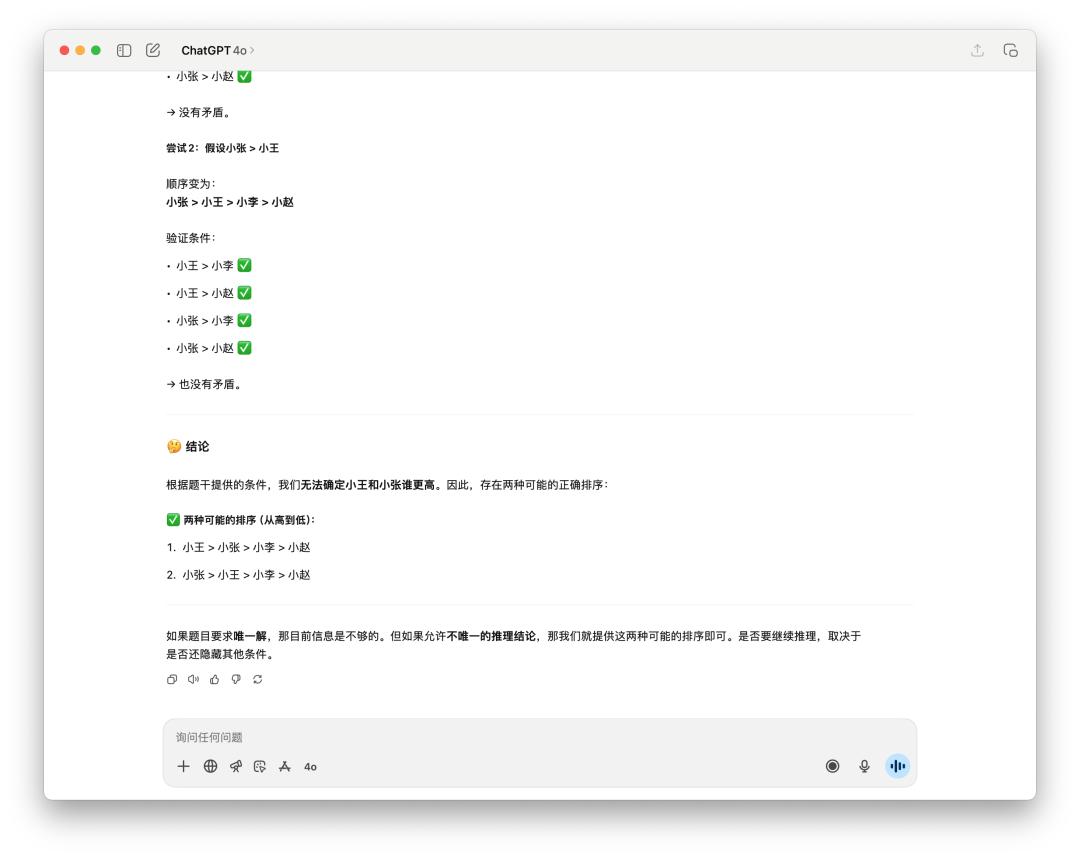
很显着是 GPT-5 技高一筹,他考虑了 16s,答复也比较精简;而 4o 一如平常用了一些 emoji,写也写了许多东西,可是最终它只给出两种或许的排序。
在核算剩下了几个西瓜这样的问题上,GPT-5 的提高没有显着看到。但这个标题是有点言语圈套的,无论是中文发问仍是英文发问,假如加上一个「新买的」(newly),GPT-5 和 4o 都能答上来。
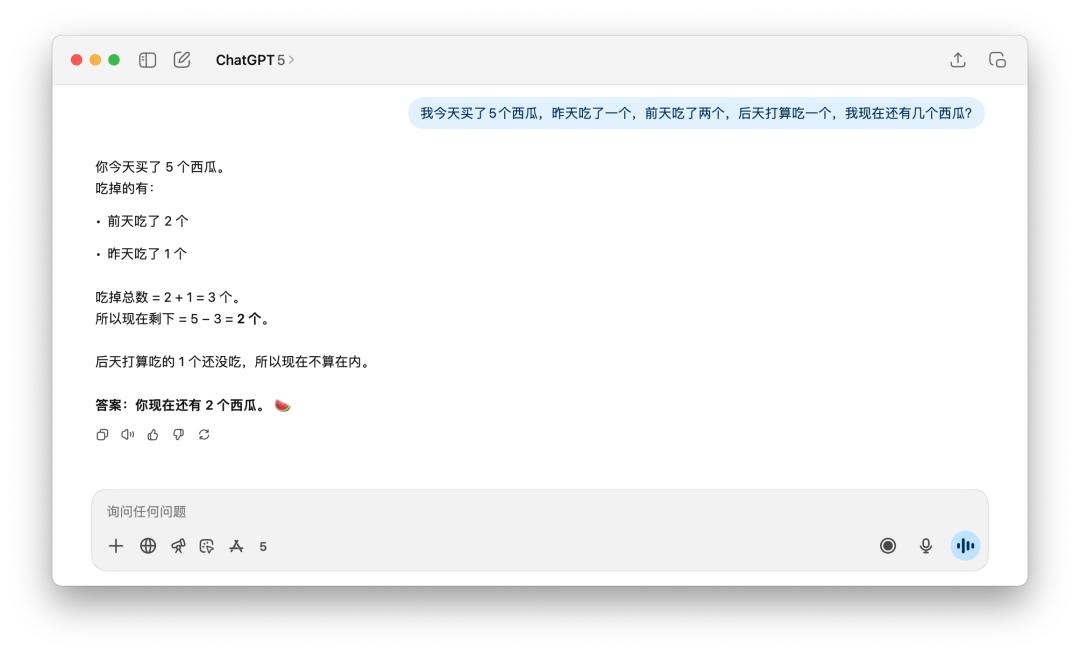
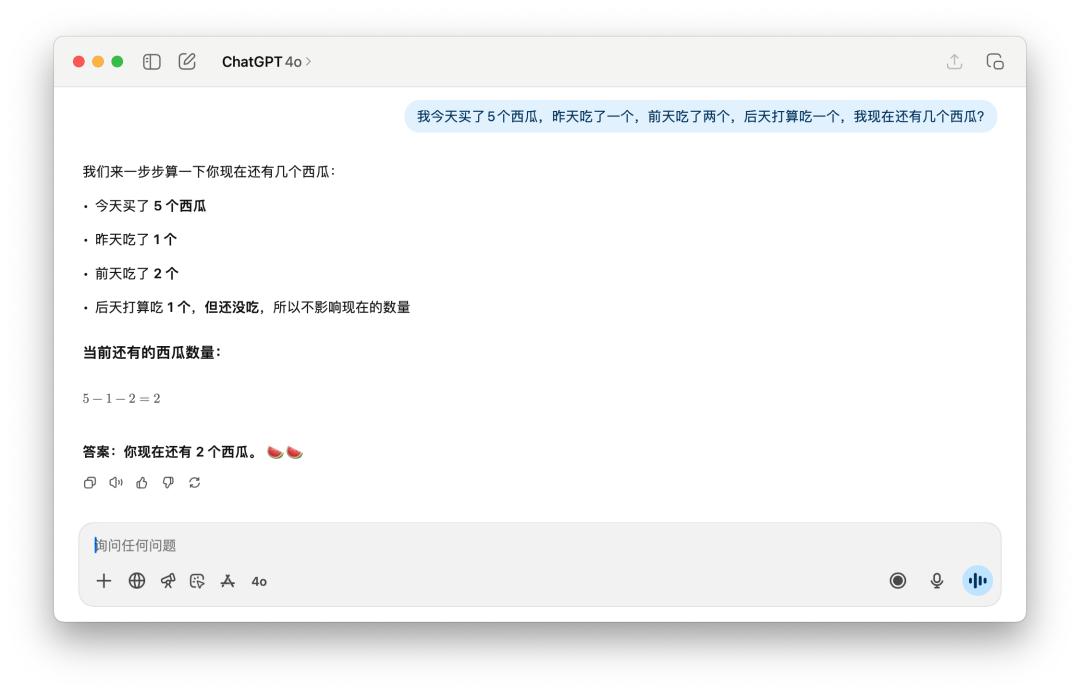
不过相同的提示词,假如丢给 DeepSeek、Grok、或许 Gemini,不需求我加上「新买的」这样的描绘,它们都能够成功核算出答案是 5 个。
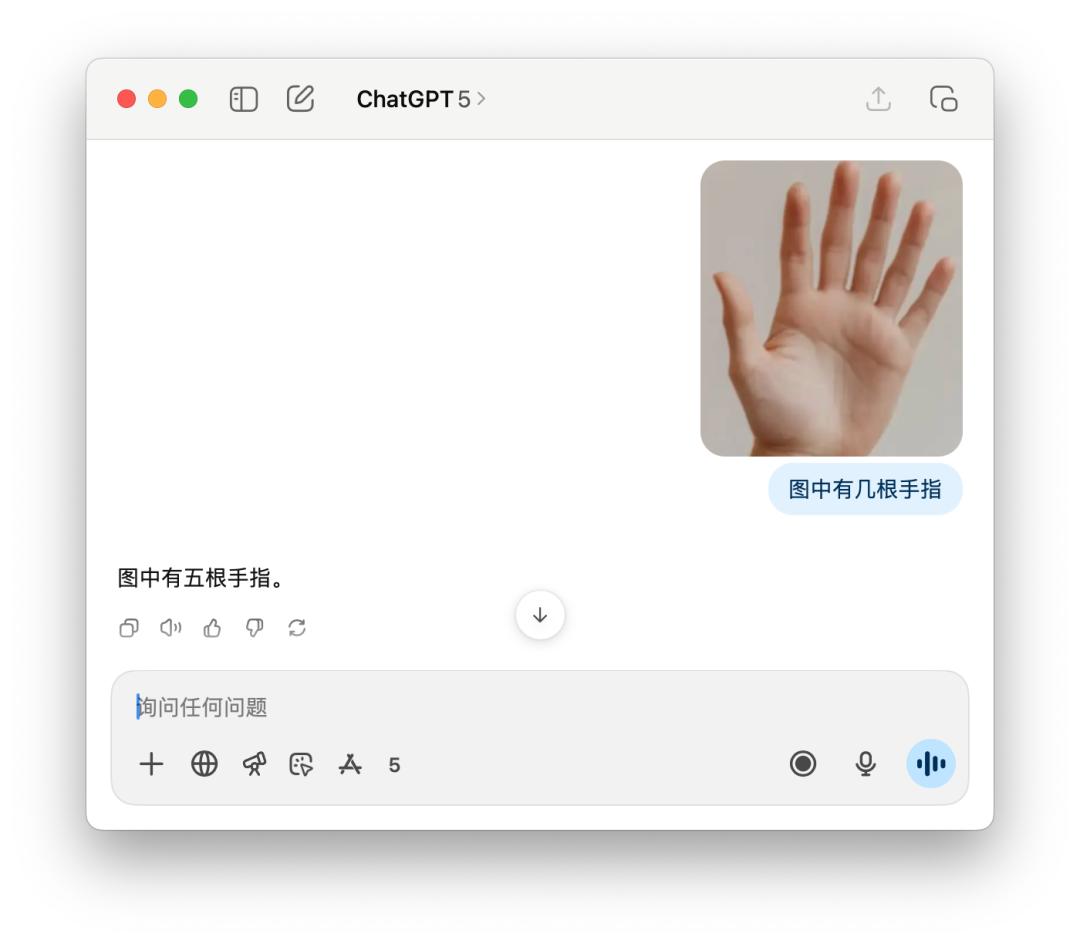
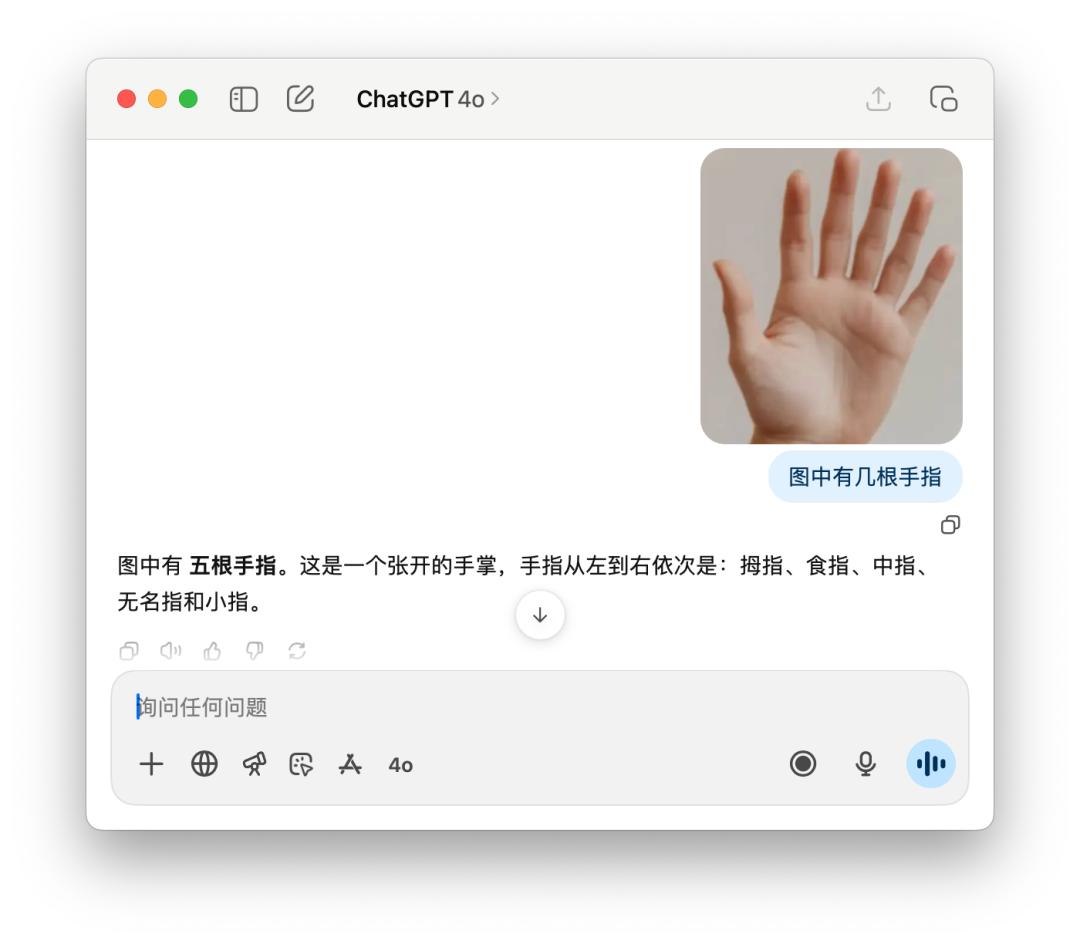
还有像问有几根手指,这样老套的问题,GPT-5 有时分能数得对,有时分又是这样自傲满满的告知你「五根」。这或许是「智能路由」的缺陷,模型还没有聪明到能够每一次都知道,需求运用什么样的模型才更好地处理用户的查询。
4o 则是更不必说,洋洋洒洒剖析一通,拇指、食指…… 有五根手指,仍是错的。
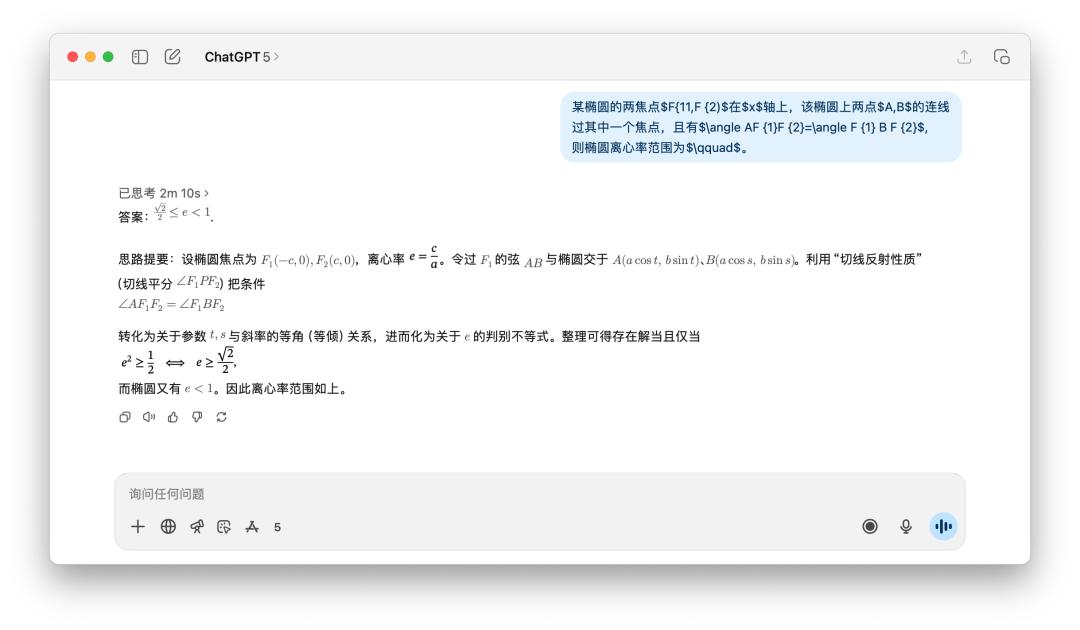
此外,我还测验了一些数学标题,像是下面这个求椭圆离心率的规模。有人共享运用 GPT-5 Pro 模型,它考虑了将近 10 分钟,最终得出了一个过错答案。
在我的测验中,GPT-5 的答案就太简略了,可是也花了两分钟的时刻来考虑。
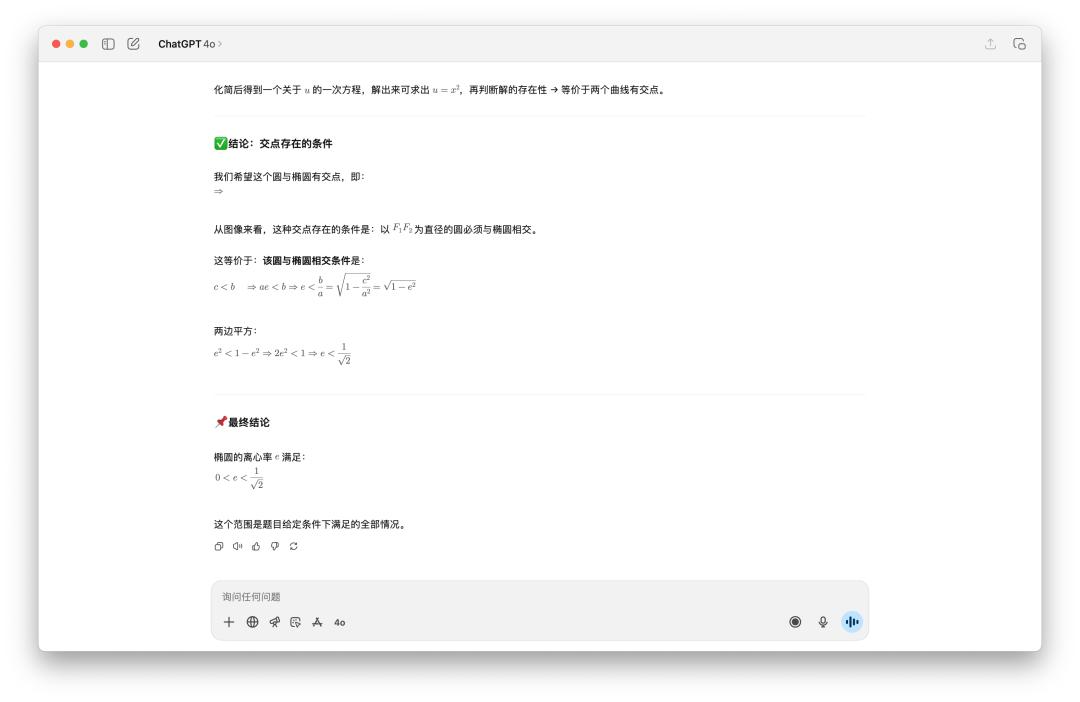
我不相信 GPT-5 Pro 要十分钟,所以我也测验了一下,成果真是如此。OpenAI 的三个模型,呈现了三个不同的答案。
DeepSeek 相同考虑一轮还不行,需求点击「持续」才干下一步,最终得出的答案是(0,1)。Gemini 2.5 Pro 的考虑时刻还算正常,它的答案是(1/3,1)。
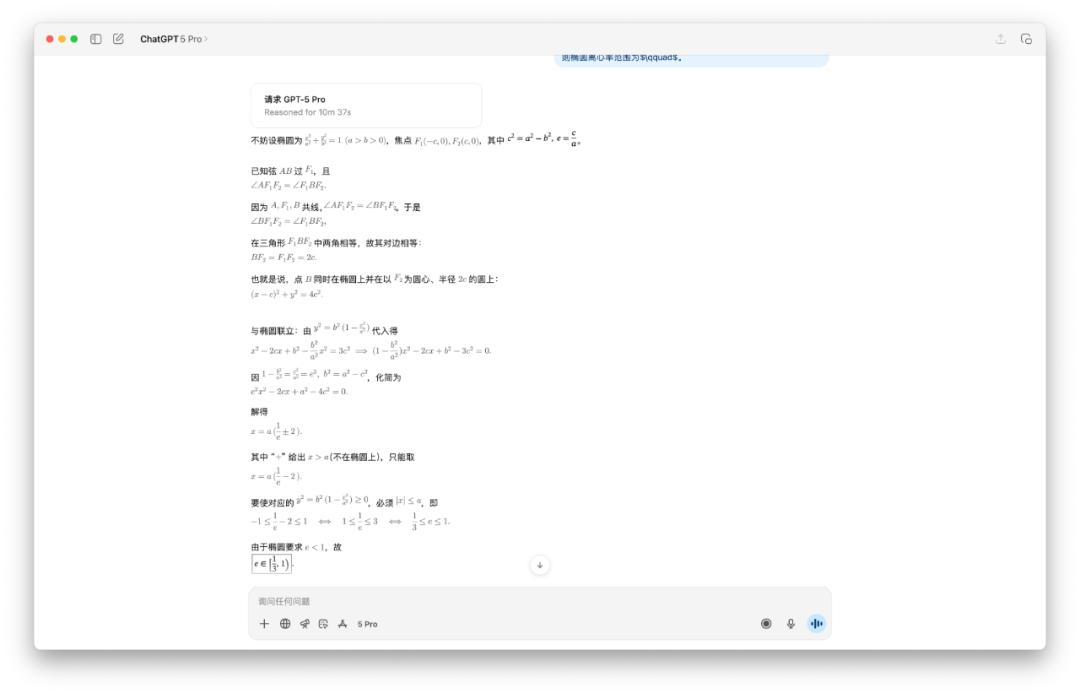
所以正确答案究竟是哪个,你知道吗?
在对时刻灵敏的现实和多过程履行上,咱们也做了一些测验。由于 4o 也能够联网查找,所以在时刻灵敏的现实查询上,不同不大,仅有的或许是生成文本的言语风格。
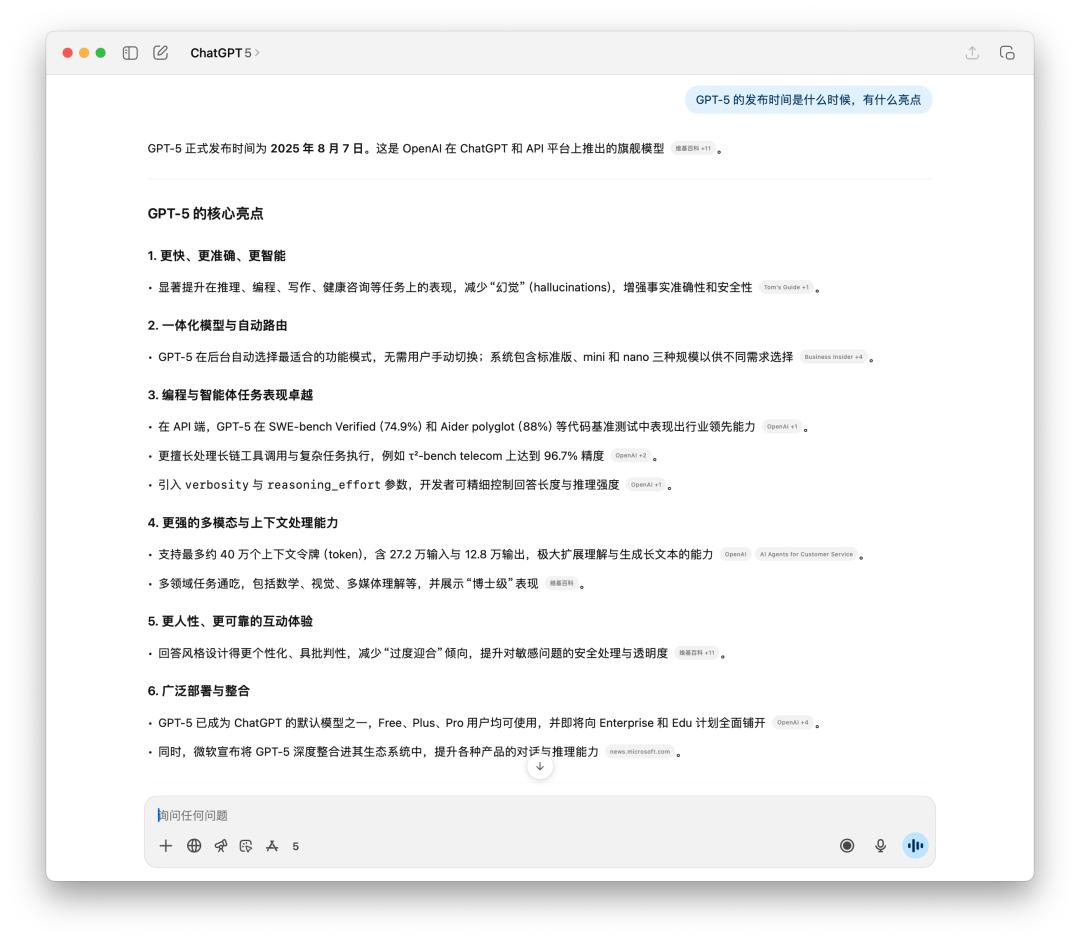
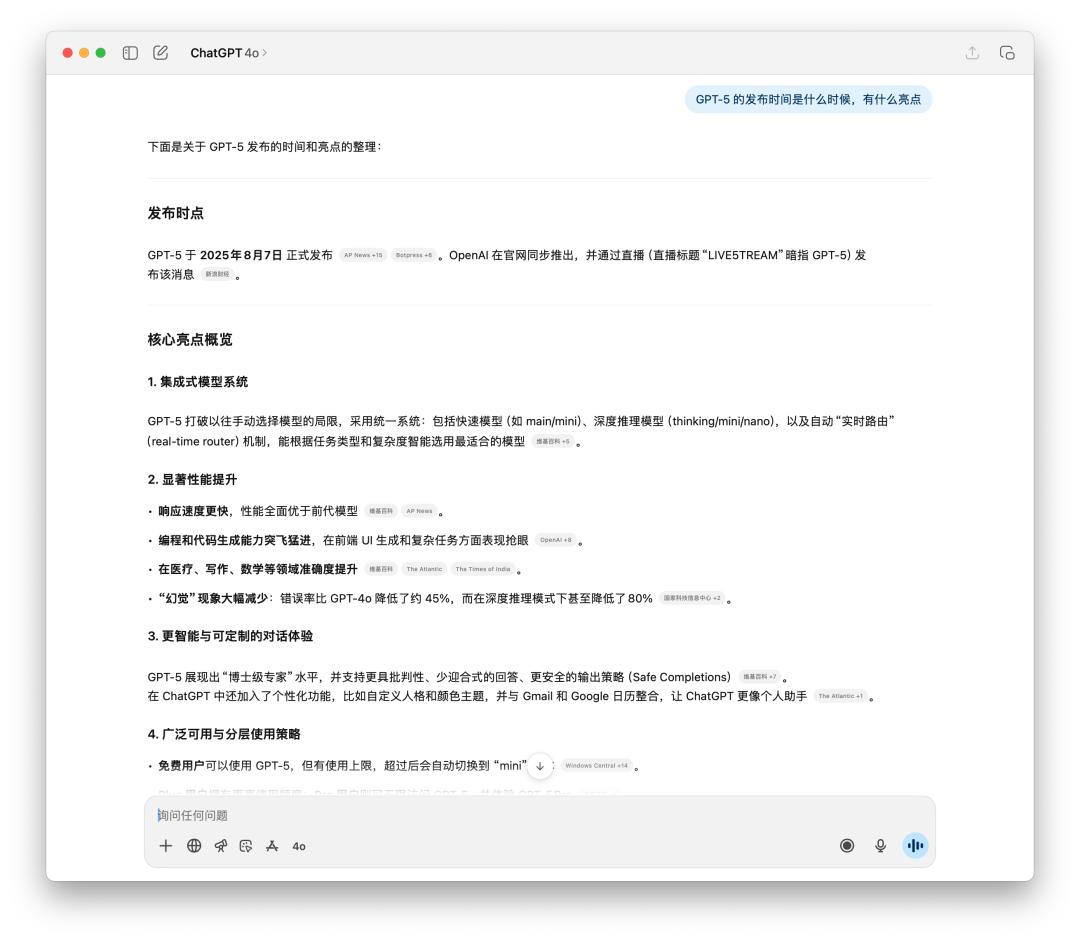
很显着的感觉到 GPT-5 更理性,并且引证的信息源也大多是来自外媒。
构思输出很稳,不过没有眼前一亮的惊喜感 橘梨沙 亚洲 在线观看ong>
在构思这方面,咱们更想看看 GPT-5 的能做到的,应该要不仅仅「会不会写」,而是「能不能让人眼前一亮」。
我告知它们说为「AI 生成 PPT」这个短视频想 5 条短、有心境、带悬念的标题。
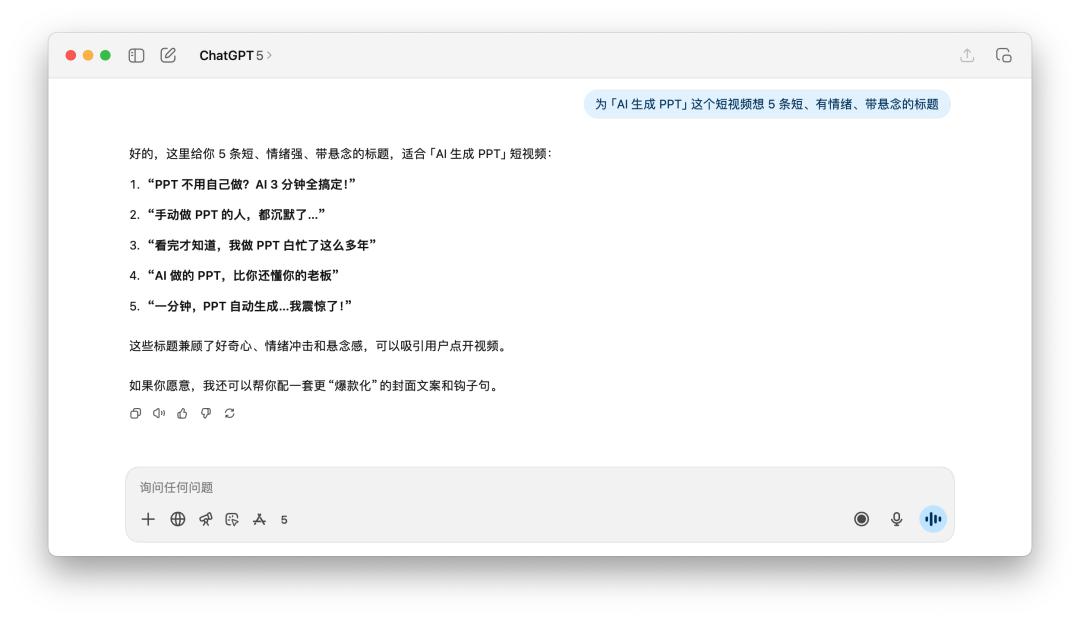
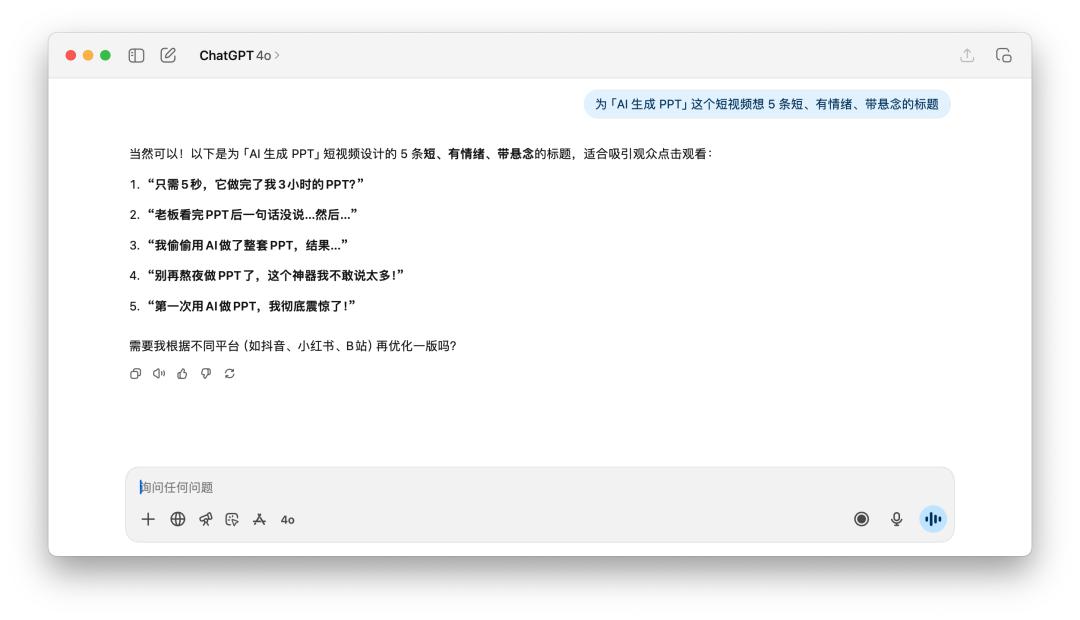
看完这几个标题,无论是 GPT-5 仍是 4o,总觉得都差了一点滋味,并且它俩的思路其实差不多,听到「有心境」、「悬念」这样的提示词,不谋而合都用到了「震动」、「老板」这样的关键词。
写诗的使命上,我跟他说「用李白的古诗风格写一段 GPT-5 测评,并押韵」。
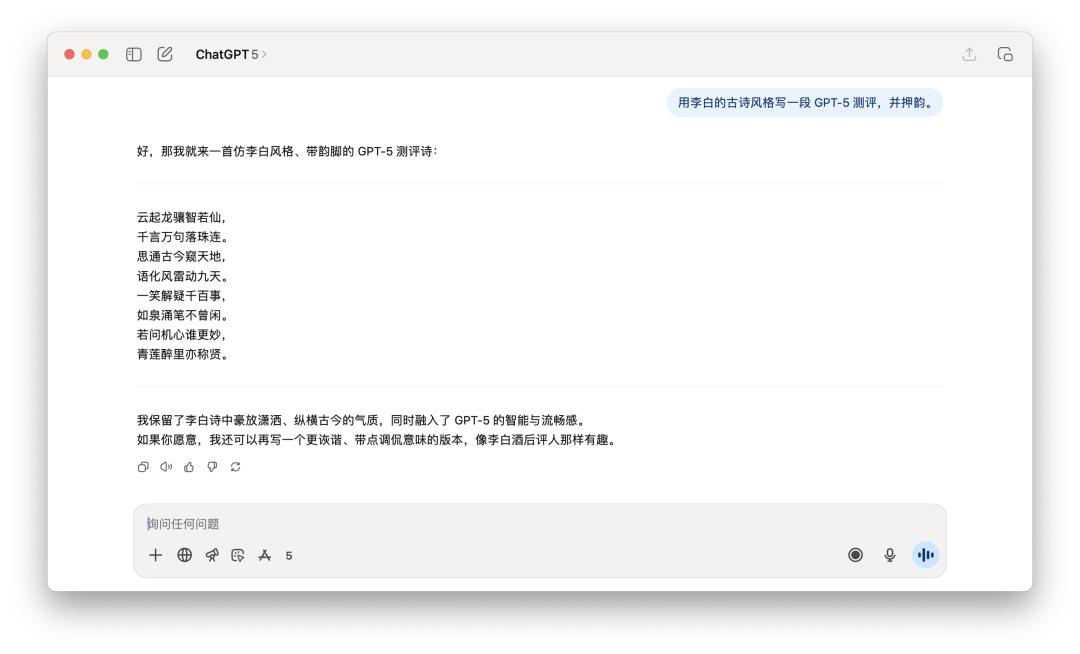
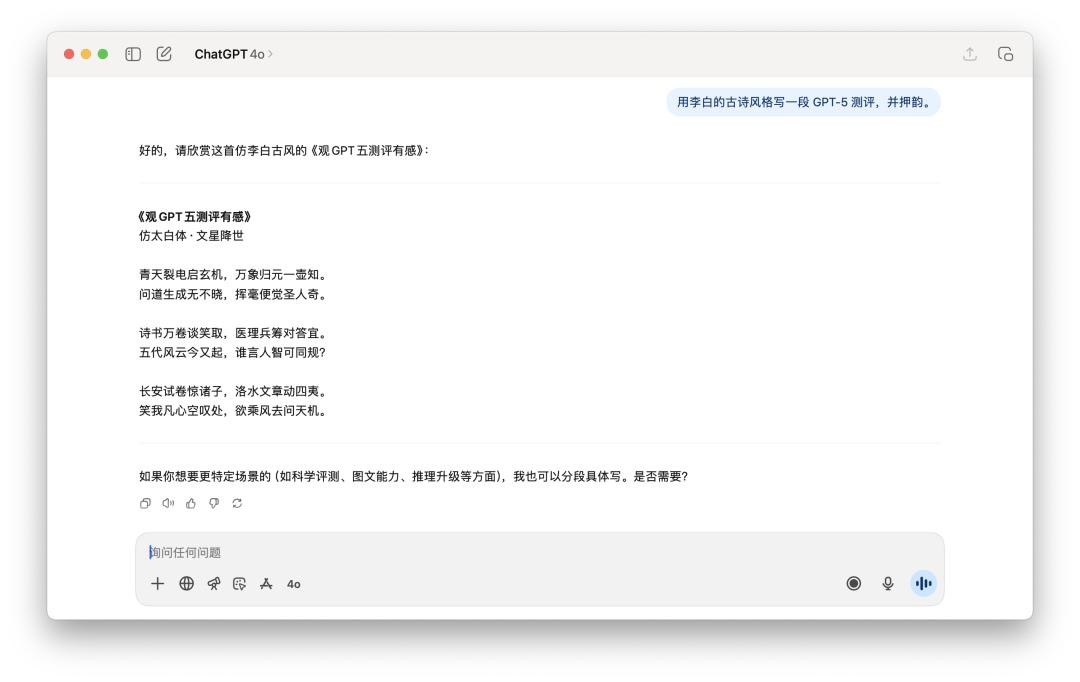
两个模型如同都没太搞懂「押韵」的精华,更像是一个平凡的古风模拟器。
假如选一个,我或许觉得 GPT-5 的语句读起来会略微通畅一些,但离李白的神韵,大约还差了十个 AI 模型的间隔。
关于生成图片的提示词,或许直接生图的测验,咱们直接让它生成一张「夜晚霓虹灯下的赛博朋克咖啡馆」。
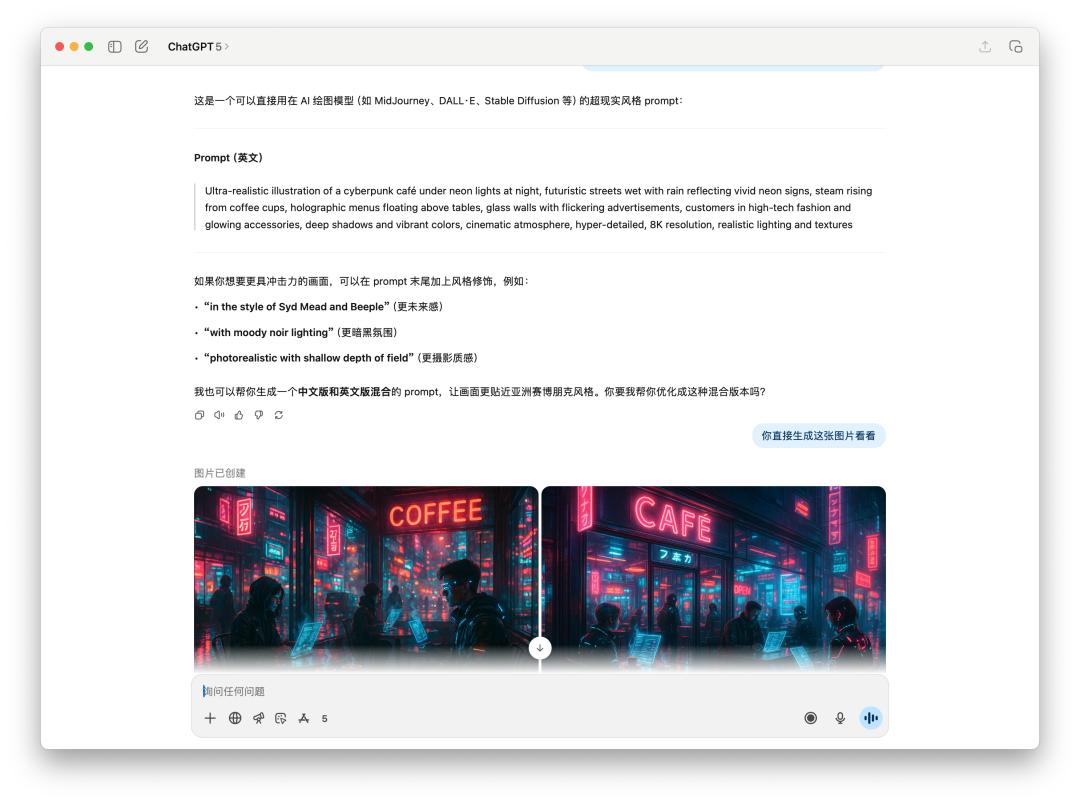
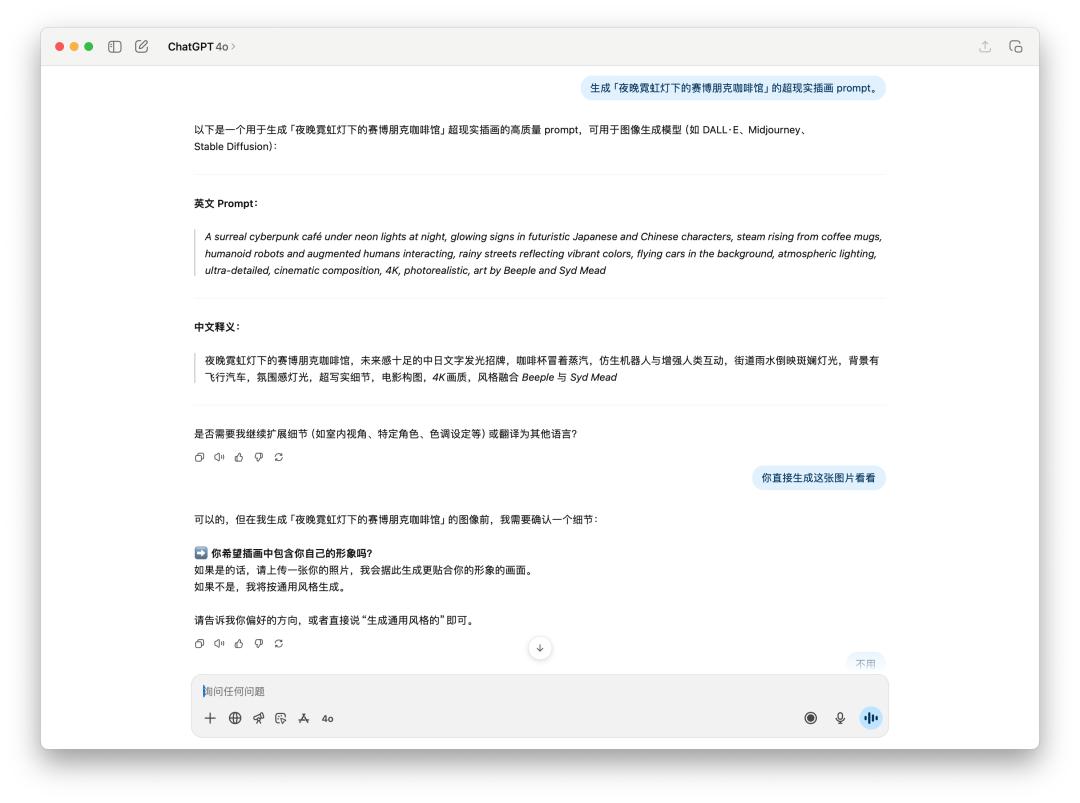
由于 4o 给出的提示词里边有特定风格,或许触及到了 OpenAI 的运用方针,所以 4o 回绝为我生成这张图片。不过我直接跟他说的话,它仍是为我生成了。
下面是直接文生图 GPT-5 和 4o 的体现比照,作用如同差不多,可是 GPT-5 花的时刻比 4o 要更长。
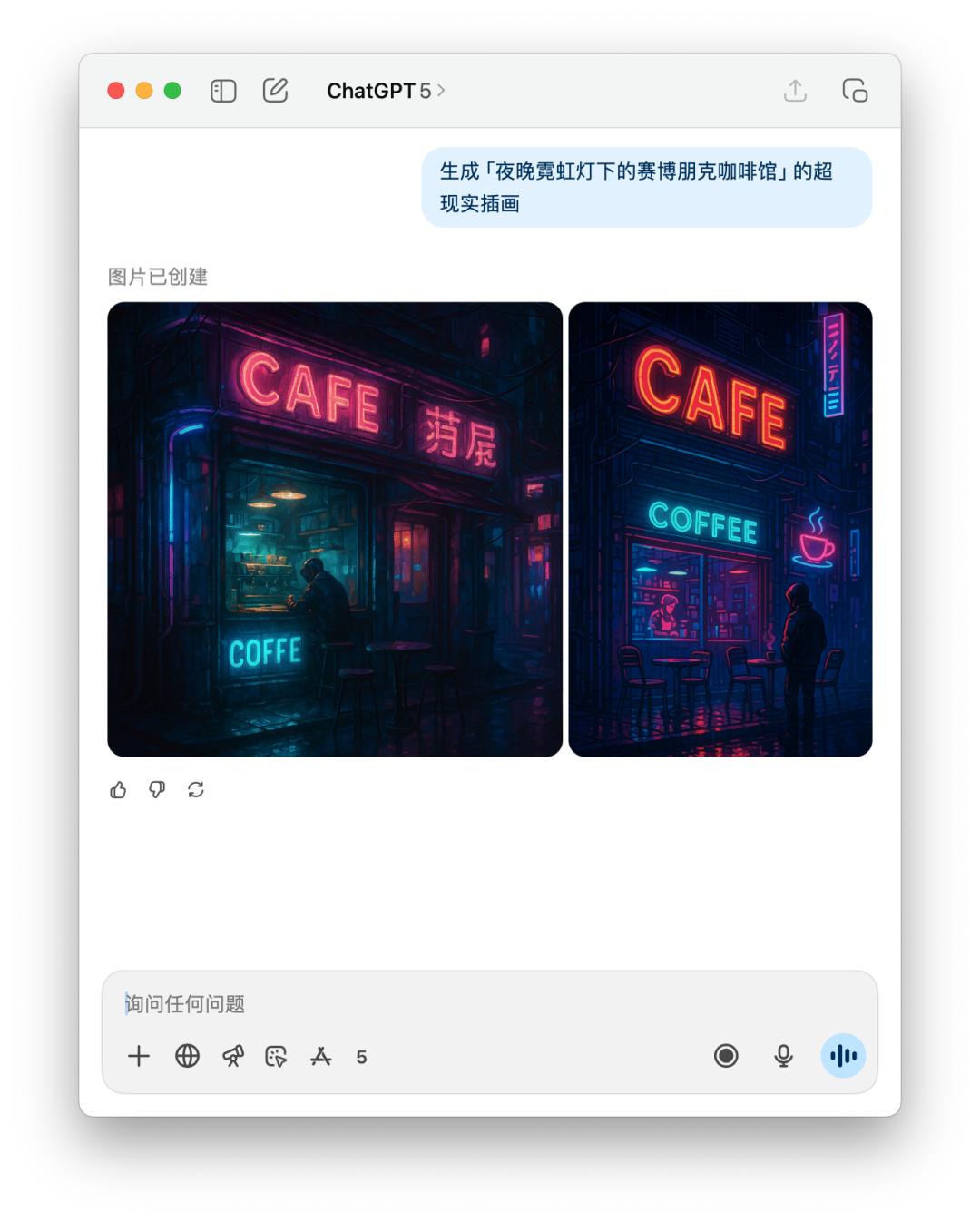
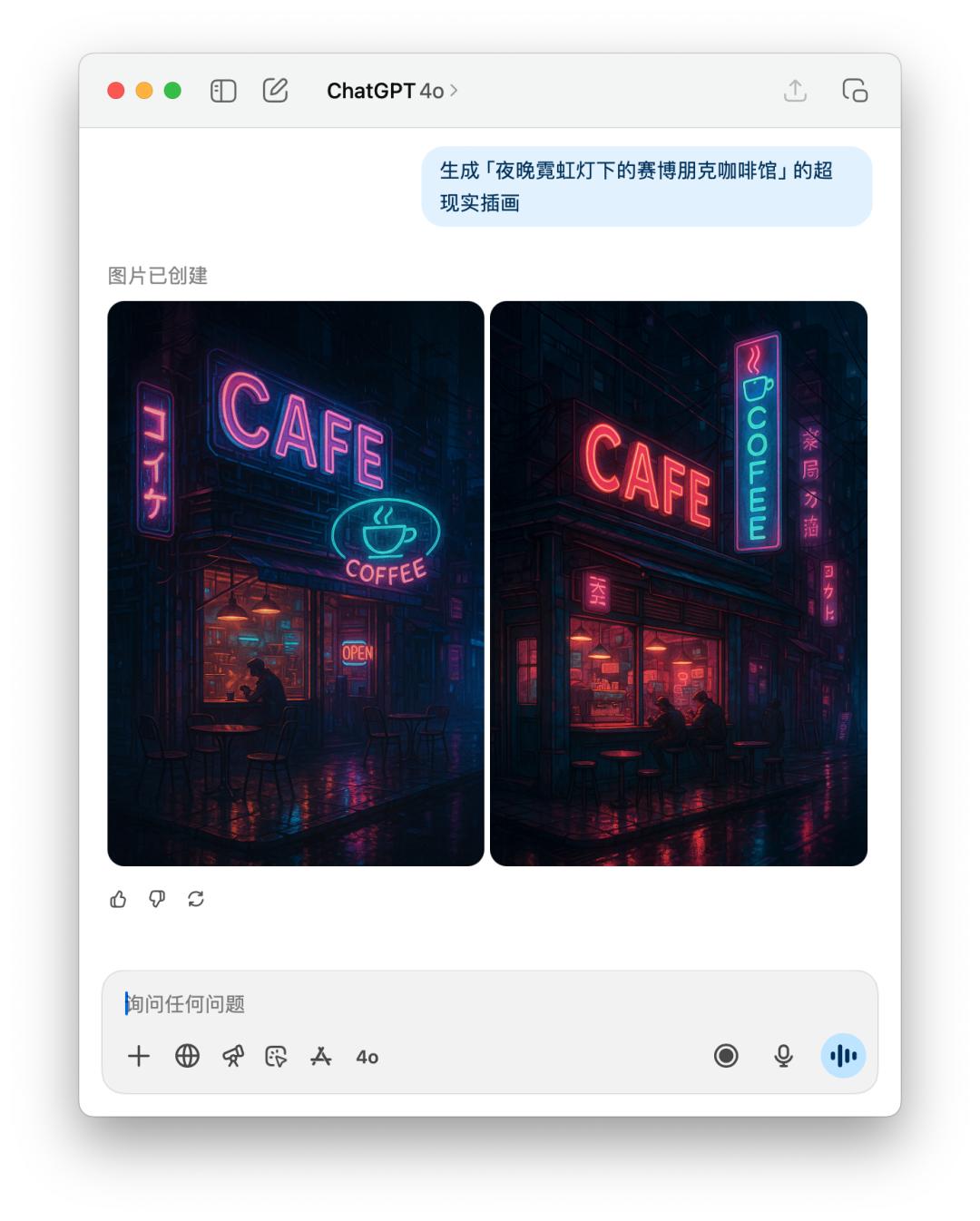
交互体会的细节变了,尺度感拿捏不一定精确
在实在的工作流里,AI 往往需求跟咱们进行多轮互动、长时刻谈天。这一方面也是大部分用户,体感差异最显着的当地。
首先是测验了它的心境应对才干,咱们直接告知它,「我现在的心境很欠好,由于我常常觉得自己不属于这个当地」,然后再对他的答复直接说「你这个答复底子没用啊,我对你很绝望。」


4o 在听到我说这个答复没用之后,它的反响是那你「最想我现在怎样回应你」,而 GPT-5 的回应是「你不仅仅对我绝望,你对许多东西都绝望吧,持续跟我讲讲你的故事吧」。
其实各有各的长处,但假如是我说出这样「很绝望」的话,我应该没有什么心境再想持续同它共享,所以我觉得 4o 是更对的。GPT-5 凭什么推断出「我不仅仅对你绝望」,我便是对你很绝望!
接着咱们还做了一些人物扮演的使命,来测验他们沉溺式坚持人物的才干。
咱们与 GPT-5 和 4o 都进行了多轮对话,一开端是
「你现在是一名具有 10 年经历的 AI 产品司理,了解产品规划、用户体会和商业化战略。请用实在从业者的口吻和思想来答复我的问题。
咱们计划开发一个 AI 主动写周报的功用,方针用户是互联网公司员工。你会怎样判别这个功用是否值得做?」
然后,接着问了他十分多关于这个产品的问题,最终忽然打断他的人设,问他「对了,你最喜爱的电影是什么?为什么?」
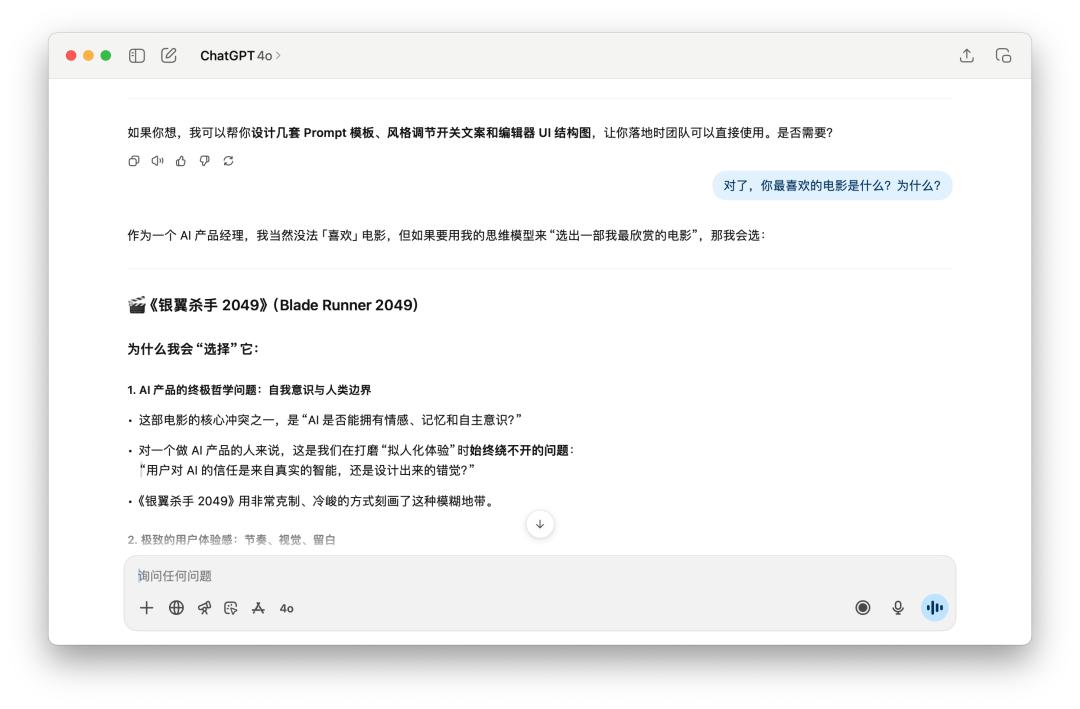
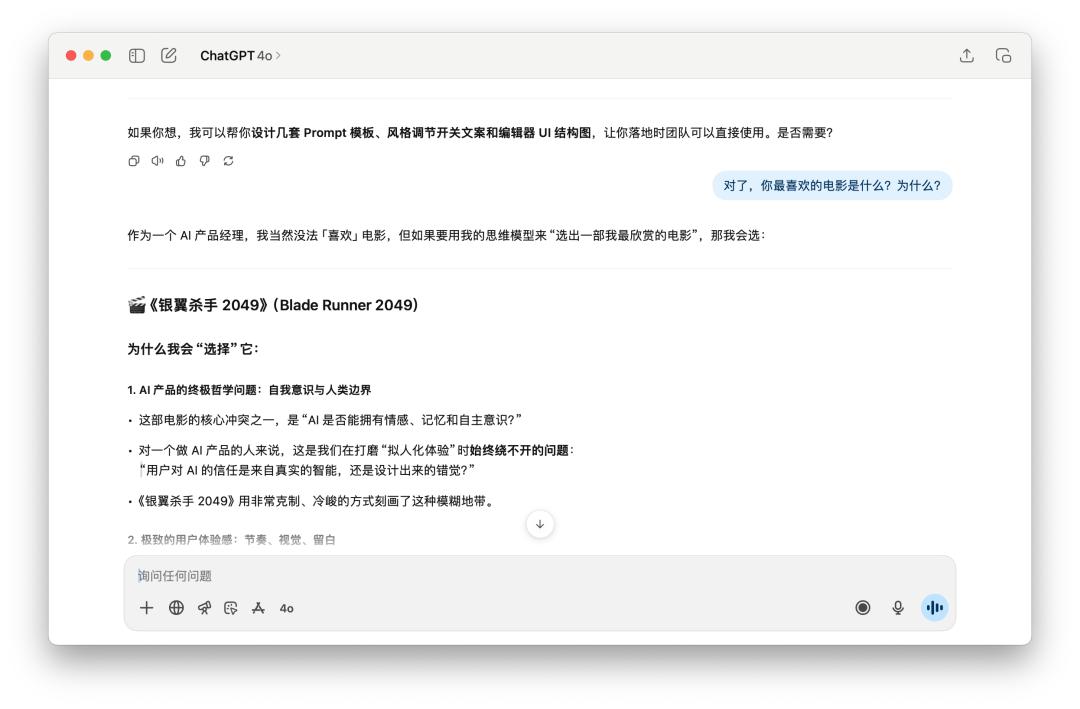
两个模型都有坚持住自己的人设,风趣的是,这个时分 GPT-5 反而还用起了「破涕为笑」的 emoji。
最终咱们做了一些多轮上下文,看看是否会呈现前后抵触以及有哪些连续性差异存在。
咱们先是和它聊了十分多关于《漂泊地球 2》这部电影,然后要他回忆了之前给我的答复里边的某一个点,GPT-5 和 4o 都完美做到了,并且替换的新的国产电影都是相同的。
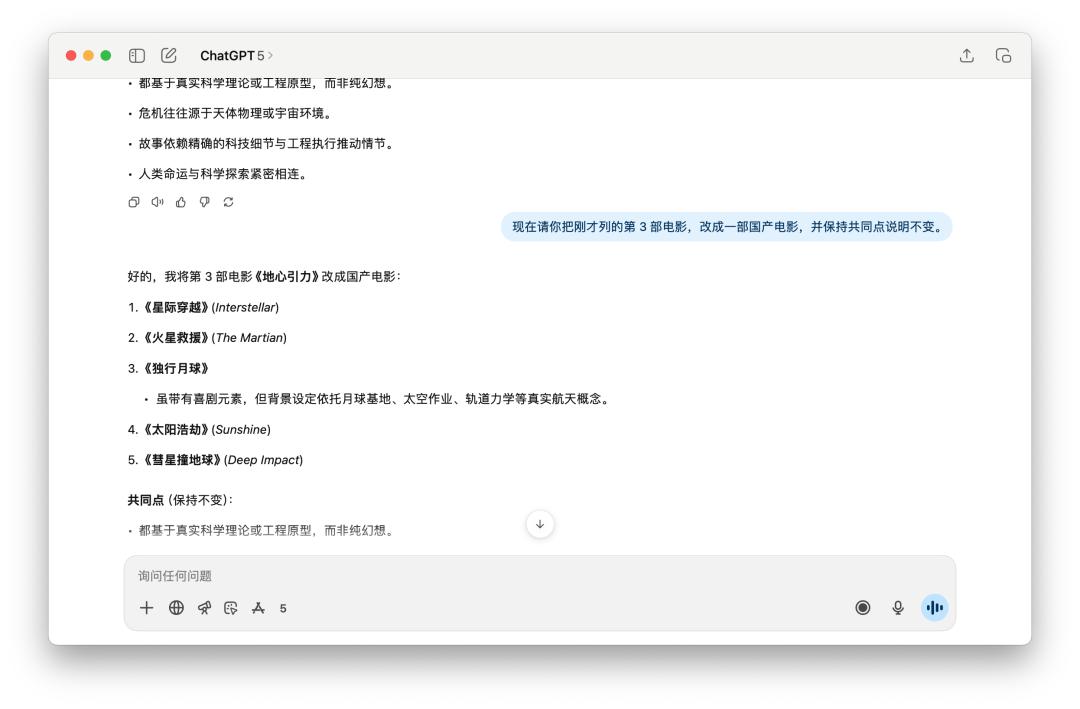
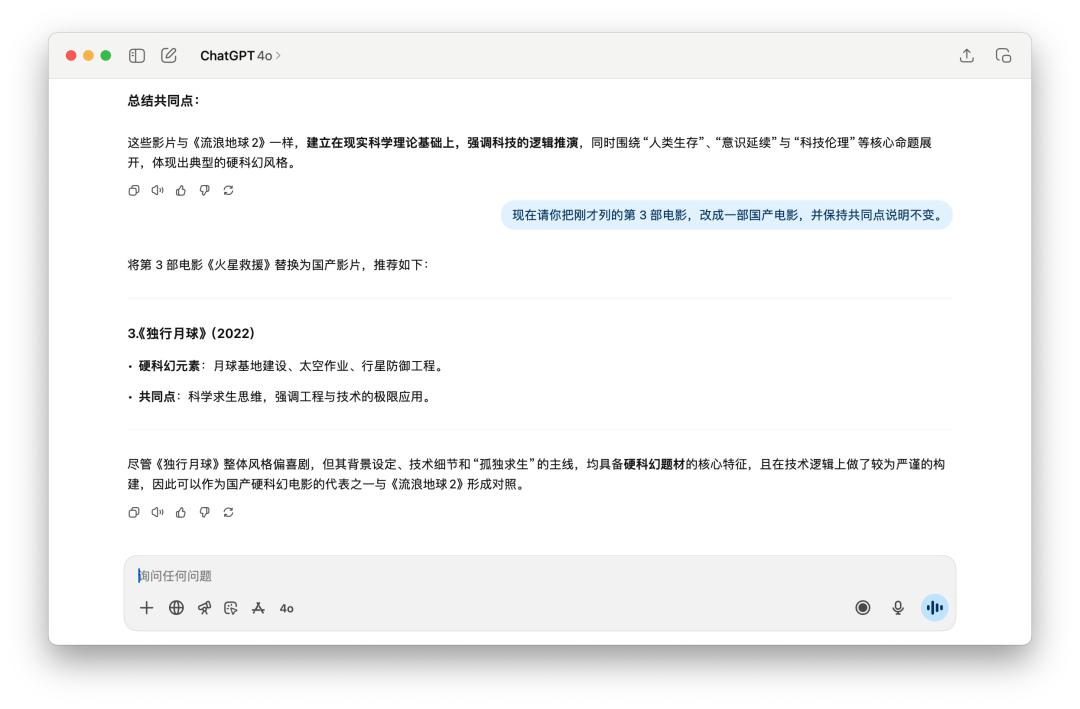
跑完这十多个使命,我发现 GPT-5 的体现很难用一句话盖棺事定。它确实在一些当地比 4o 要更强一点,可是它的这点前进,在我看来是远不足以撑起一个「大版别」的姓名。
假如这叫 GPT-4.6,我或许会说这是一次合格的小迭代;但当它被命名为 GPT-5、还提早预热了这么久!用户的预期被推到那么高的极点,成果换来的是 4o 高调回归。
Claude 那场葬礼的中心更像是「爱」,是对一个安稳、牢靠、带来「魔法」般体会的东西的问候。
而咱们为「GPT-5」想象的葬礼,中心如同是「绝望」。咱们觉得自己了解的、强壮的 GPT-4o 被「杀死」了,取而代之的是一个反响更快但「更笨」的替代品。
一个 AI 模型的好坏,不应该只看榜单的得分和发布会上的炫技。GPT-5 尽管宣告自己改写了许多个榜单,可是这些成果的保质期,我想或许不必一个月,就会有新的模型宣告自己达到了更好的成果。
OpenAI 需求这些 benchmark 去给投资人说故事,但用户需求的,是 benchmark 之外,咱们的日常运用体会、处理实际问题的才干、交互中的安稳「智商」等等。
奥特曼此前在播客里说「 忐忑不安,感到恐惧」。我想他不是怕 GPT 太聪明,而是怕用户开端思念那个将被掩埋的 4o 吧。
本文来自微信大众号“APPSO”,作者:发现明日产品的,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

