 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
GPT-5 黑船来袭 无删减没有惊喜,但信号拉满
在GPT-4发布两年之后,阅历屡次“跳票”的GPT-5总算上台。
北京时刻8月8日清晨1点,OpenAI举办了一场逾越一小时的发布会,体系展现了GPT-5在智能水平、编程才能、使命推理等维度的功能迭代。
但比较此前GPT-3到GPT-4所带来的全方位晋级,许多人表明,这次GPT-5并没有带来更多的惊喜,从发布会规划、产品亮点、到功能晋级,都显得较为平凡,相较当时干流SOTA模型,提高起伏并不显着。
反倒是价格战略成了此次发布的最大亮点。GPT-5的API调用价格仅为前几日发布的Claude Opus 4.1的1/15,显着低于Gemini 2.5 Pro,在当时大模型市场上展现出极强的性价比。
近两年,跟着AI东西开端席卷各行各业,人们巴望AI可以替代重复繁琐的作业,也在忧虑自己是否会被AI所替代,这也是GPT-5发布前备受注重的原因之一。但就现在GPT-5的才能打破来看,人类智能在通往AGI的路上仍有很长一段路要走。
回顾过去几年GPT的迭代进程,不只是很多AI公司争相仿效的目标,也是整个大模型职业开展的缩影。而此次GPT-5相对平凡的体现,虽然打破了外界对大模型技能继续打破的惯性认知,但某种程度上,也在大多数人的意料之中。
比较AI鼓起阶段群众关于大模型技能的过高展望,市场上有关大模型参数打破的谈论正势渐弱小。比较起技能打破,人们开端愈加关怀的是,AI怎么更有效地渗透进日常日子。
从GPT1到GPT5,GPT的未来要走向哪里?
自2018年OpenAI发布首个大模型GPT-1以来,GPT系列现已走过了七年。
2020年GPT3的呈现,让大模型参数规划从15亿直接拓宽到了1750亿,也因而经过“上下文学习”才能,摆脱了对很多标示数据的依靠,使大模型可以开端作为功率东西运用。
两年后,根据GPT-3.5构建的对话式模型ChatGPT上线,进一步推进大模型走入C端日常,成为通用AI运用的重要落地转折点。
随后GPT-4的全面晋级,更是在完成万亿级模型参数的一起,让大模型在单纯文本输出的基础上,完成了图画的交互提高。
尔后一年里,GPT发布的多款模型,都在环绕图画、语音互动等多模态才能迭代; deepseek的横空出世,将推理模型带向了群众视界,上一年OpenAI连续发布了O1、O3系列产品,将杂乱推理作为了功能优势,开端着重对科学、编程等专业范畴的帮忙才能。
与此一起,环绕大模型参数量的庞大叙事开端逐步消失,改变为对多模态、长文本等细节才能的寻求,以及对医疗、教育等落地场景的谈论。正因如此,大模型产品形状也开端从单一模型转向了多版别并行。
到现在,OpenAI已构建起由GPT系列(主打对话交互)、O系列(聚集杂乱推理)以及图画/视频生成模型(支撑多模态创造)组成的三大产品矩阵。
在本次晋级的GPT-5中,GPT进一步一致了O系列的推理才能和GPT的快速呼应,比较较deepseek在模型运用时,自主挑选是否运用深度考虑形式,GPT-5的差异在于可以主动判别对话类型。
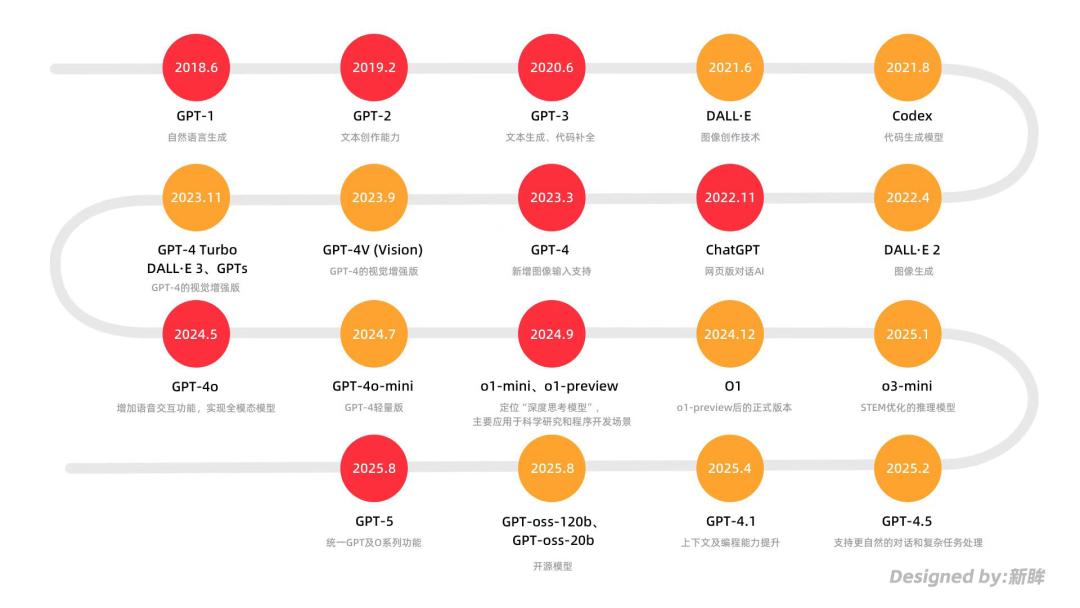
OpenAI中心产品发布时刻线
除此之外,在此次发布会中,黑船来袭 无删减OpenAI初次一起推出了4个版别,标准版GPT-5、轻量级的GPT-5 mini与GPT-5 nano,以及面向企业与高档订阅用户的GPT-5 Pro(需企业授权或月付200美元)。加深了按需定制、分层定价的SaaS化途径演进。
这种改变也意味着,关于AI公司来说,竞赛的门槛不再仅是技能打破,还在于是否具有构建产品体会、建立商业模型、整合跨界资源的归纳才能。
GPT-5难产本相:大模型晋级为何越来越难?
DeepSeek上线所带来的用户量激增,不只向外界证明了开源模型的商业化可行性,也进一步加深了大模型公司对“先发优势”的注重。当模型功能间隔趋于收敛,前期关于用户心智的抢夺上升为榜首要义。
正因如此,跟着GPT-5面世的风声不断,最近一段时刻,各大厂商开端纷繁加快竞跑,相继推出新品。
字节在两个月前将豆包更新至1.6版别,阿里也在昨日推出了Qwen3-4B-Instruct-2507与Thinking-2507双版别,MiniMax近几日发布了新一代言语生成模型Speech 2.5,智谱也在上月底发布旗舰模型GLM-4.5……一场集中式更新潮,给寂静良久的大模型赛道掀起了又一波浪潮。
但当咱们把时刻拉长来看,这波密布的模型上新趋势,间隔上一次“百模大战”的盛景,现已过去了一年多。
大模型的更新趋势正在逐步放缓。不只如此,相较GPT-3到GPT-4参数暴升、多模态打破、上下文显着增强的跃迁,近期多款新品的提高起伏也显得较为有限,大多数模型的晋级和GPT-5相同乏善可陈。
很多人把背面的原因归结为数据瓶颈。
上一年万众瞩目的Orion,项目开发时长逾越了18个月,从前被寄予厚望,原计划作为GPT-5推出。结果在验证时,功能却远未到达预期,终究只能被降级成GPT-4.5,在本年2月静静上线。
据业内人士称,Orion之所以失利,最中心的原因在于,团队摸到了预练习阶段的天花板。跟着练习数据的不断扩大,高质量网络数据存量不断削减,直接导致了模型练习作用的下降。
除此之外,跟着大模型参数量不断添加,硬件水平所带来的掣肘也在越发扩大,据媒体报道,有开发人员泄漏,OpenAI在上一年年底所推出的推理模型O3,之所以可以完成中心的功能提高,首要依靠于运用更多的英伟达芯片进行开发。
更进一步的问题在于,群众关于AI错觉、AI味的抵抗正在呈现更为急进的态势。
GPT-5发布前夕,奥特曼曾在交际渠道共享了模型对话才能的演示。但出人意料的是,谈论区注重的焦点已不再是功能指标,而是GPT频频运用破折号的言语习气。
此前OpenAI在本年2月推出的GPT 4.5,中心功能晋级也在于提高模型情商,削减AI痕迹。与此一起,在有关GPT-5的威望测评数据中,也表明出AI事实性错觉的大幅削减。
但正如很多网友所吐槽的那样,比较较数学才能的准确度提高,GPT-5在写作流通度、情商体现上却远不如GPT 4.5。
某种程度上来说,AI的黑船来袭 无删减思想机制和生成原理,注定了“事实性错觉”始终是一种概率性存在。
Meta首席AI科学家杨立昆从前对当时干流的LLM背面的自回归模型表明质疑,以为其经过猜测下一个词来生成文本的形式,实质上无法孕育出真实的智能。
这一判别也对过去大模型练习逃不开的Scaling Law道路进行了质疑,即单纯添加参数数量并不能使得AI更好的拟合人类智能。背面的原因在于,两者在思想结构上存在实质不同,前者是从更大、更多的参数中,以最小的本钱安排信息;而后者则为了在不确定中生计和繁殖,具有更强的冗余性和含糊性。
AI Agent落地,大模型要让位?
一直以来,环绕ChatGPT的订阅收费、API接口调用是OpenAI的重要盈余来历,但跟着本年AI Agent 的很多呈现,大模型公司的商业化重心,开端产生了搬迁。
上半年,OpenAI发布了两款根据ChatGPT的AI Agent,一是可以替代用户操作浏览器,自主执行使命的Operator;二是可以辅佐做深入研究,生成专业研究报告的Deep Research。
据The Information发表相关文件表明,OpenAI已奉告投资者,估计到2025年底,AI Agent及其他新产品的算计销售额将逾越ChatGPT。
与此一起,比照上一年全年37亿美元的营收, OpenAI估计本年的营收能到达127亿美元,比较上一年的营收估值足足增长了2倍以上。背面最重要的驱动力之一,就是AI Agent。
事实上,AI Agent的商业化迸发并非OpenAI独享。以辅佐编程为中心的“vibe coding”编辑器Cursor就是典型代表。
凭仗多行智能重构、代码主动补全和代码库查询等功能,Cursor付费用户已超36万,最新估值较年头激增三倍。与此一起,曾引发全网“账号抢购”热潮的Manus,虽然被曝“出逃海外”,仍然反映出AI Agent在笔直细分范畴的极高用户粘性。
AI Agent的鼓起,一方面得益于大模型底层功能的继续提高,另一方面则源自各笔直范畴对定制化智能东西的刚性需求。这种需求不只使得Agent可以更精准、高效地服务专业场景,也催生了更强的用户依靠。
但需求指出的是,AI Agent在实践运用中一般面对更高的Tokens耗费,这对创业公司尤其是资金实力有限者而言是沉重的压力。Manus的“出逃”,必定程度上折射出了草创团队在高本钱运维与现金流压力下的两难地步。
此外,AI Agent实质上是建立在大模型基座之上的“套壳”运用,模型才能的天花板直接约束了Agent的功能上限。相较之下,OpenAI等头部大模型厂商在底层模型研发上具有显着优势,也因而更具主导权和话语权,这也解说了为何它们不会抛弃AI Agent的开发与布局。
由此可见,大模型商业化正加快向细分场景和专门化运用搬迁。另一个与之相佐证的趋势在于,OpenAI对“大模型闭源”的保存情绪开端呈现了松动。
在GPT-5发布前夕,OpenAI时隔三年再次推出了两款开源模型:gpt-oss-120b 和 gpt-oss-20b。这一动作不只被外界视作GPT-5发布前的技能热身,也被以为是在企图回应业界对模型开源日益高涨的呼声。
与此一起,GPT-5调用价格也被进一步拉低,仅为前几日发布的Claude Opus 4.1的1/15。当模型迭代的渠道期和Agent商业化趋势一起呈现,从“卖模型”转向“卖才能”,大模型公司的产品重心正在产生实质性改变。
本文来自微信大众号“新眸”(ID:xinmouls),作者:简瑜,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

