 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
LLM总是把简略使命复杂风流三国txt下载化,Karpathy无语:有些使命无需那么多考虑
跟着推理大模型和思想链的呈现与遍及,大模型具有了「深度考虑」的才能,不同使命的泛用性得到了很大的进步。
凭借思想链,大模型可以对使命进行深化剖析,完结使命规划与拆解,然后担任长周期、杂乱度高的作业。一起,咱们也能更直观地了解模型的推理与剖析进程,从中发现履行环节中的问题,并有针对性地调整指令,以更高效地完结方针。
可以说,有了「深度考虑」的推理模型,才有了现在具有多种辅佐功用与自主才能的 AI 智能体。
但现在的大模型逐步有些偏科了。为了构建运用才能更强的智能体,对长周期的杂乱使命才能的寻求现已影响到了大模型的推理形式。
不知道咱们在往常运用 AI 东西的时分有没有发现,翻开了深度考虑后,一些简略的使命也需求许多的考虑,展现了十分冗长的思想链,而不翻开深度考虑的时分,又很难准确的得到想要的回复。
这种现象越来越显着了,尤其是当大模型进入作业流(例如编码作业)的时分,其负面效应就愈加显着。
这不,AI 范畴的大牛 Andrej Karpathy 也感觉到不对劲,发了长文推来指出这个令人无语的现象。
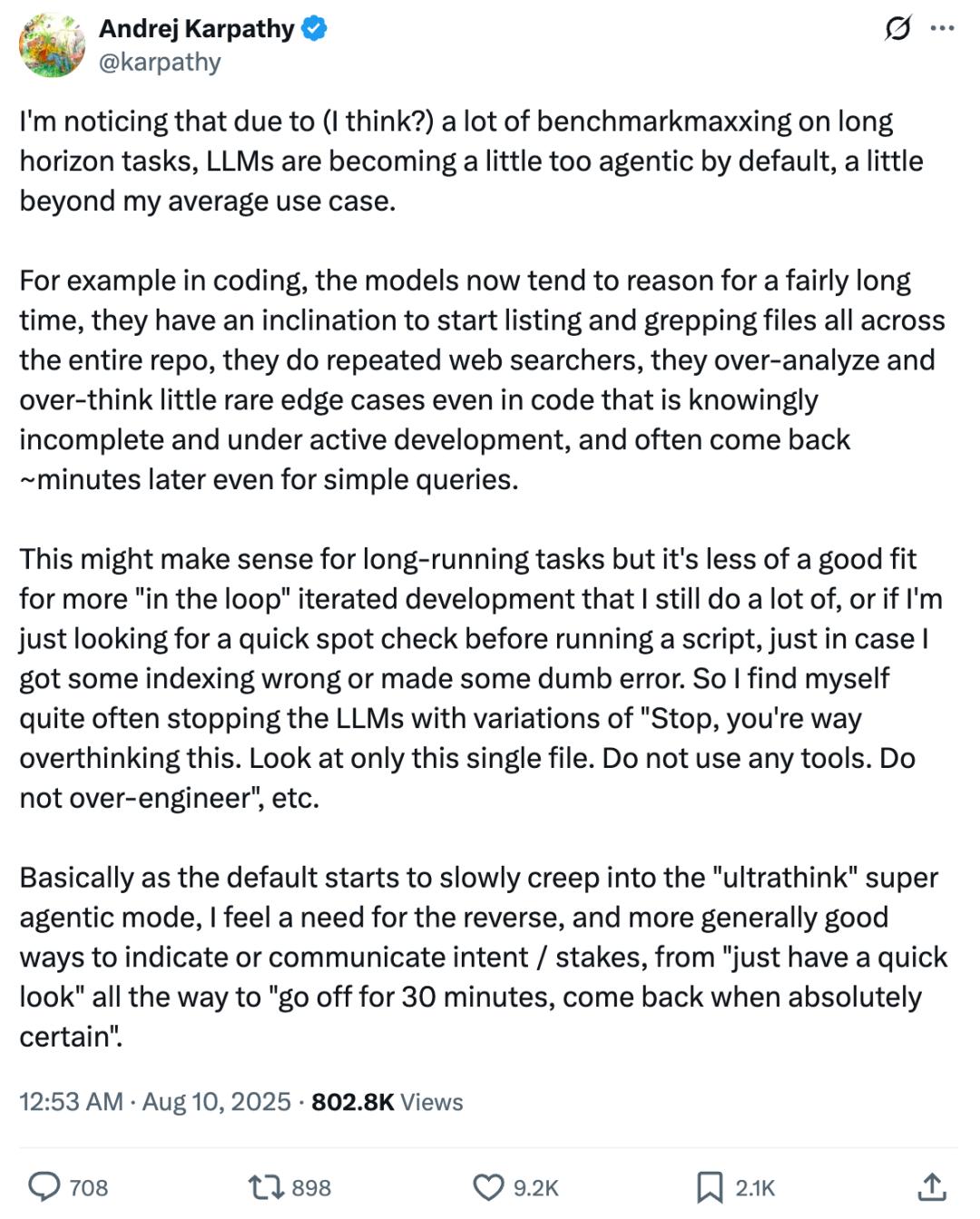
Karpathy 说,「LLM 在默许状况下正变得比我日常运用需求更具『自主署理(Agentic)』倾向,乃至有些超出了我的均匀运用场景」。
最显着的的确是编码使命,模型现在往往会进行较长时刻的推理,风流三国txt下载倾向于在整个代码库中列出并查找(grep)文件,会重复进行网络查找,对一些在开发中、且显着并不完好的代码里很少呈现的边际状况过度剖析、过度考虑,乃至在十分简略的查询中,也常常需求几分钟后才回来成果。
尤其是在简略的使命中,比方在运行脚本前快速查看索引过错或其他初级过错,底子不需求如此杂乱的使命剖析和代码处理。
因而 Karpathy 不得不常常打断 LLM,并用相似这样的指令约束它:「停,你想得太多了。只看这一份文件。不要用任何东西。不要过度规划。」
这带来了许多费事,不仅是在编码使命,咱们发现日常运用 LLM 东西时分的相似打断状况也越来越多了。
简略拿刚发布几天的 GPT-5 举个比如,发布时 OpenAI 明显意识到深度考虑的问题,所以他们着重 GPT-5 是一个集成模型,也就是说,你用它的时分不需求在不同模型之间切换,它会自己决议何时需求深化考虑。
但这个问题明显没有这么简略。记住其时 GPT-4o 模型的图画编辑生成功用很好用,但在更新到新模型后就不太相同了。
咱们给了 GPT-5 这个指令:「去除图中文字,把这张图变得高清一些,机器人的脸看起来更温文一些」,期望它可以调用图画编辑的功用。
但成果它就开端进行「深度考虑」了:

经过了 38 秒的考虑,它考虑了许多细节,但仍然未风流三国txt下载能开端运用图画生成功用,导致不得不打断它的使命进程。
或许这也是用户们无比思念 GPT-4o 的原因之一。
正如 Karpathy 指出的,跟着默许形式逐步向这种「超深度考虑」的高署理化状况挨近,咱们反而更需求一个相反的选项—— 一种更直接有用的方法去表达或传达我的目的和使命的急迫程度,从「快速看一眼」到「花 30 分钟彻底承认后再回来」都能准确指定。
网友们也苦「过度考虑」久矣,乃至为此回到了最朴素的运用方法。

关于这件事,Karpathy觉得元凶巨恶似乎是大模型「在长周期使命进步行了很多基准测验优化」,为了在基准测验上得到更好的成果,LLM的考虑就更倾向于长周期的杂乱使命的完成,因而影响了一般使命的呼应。
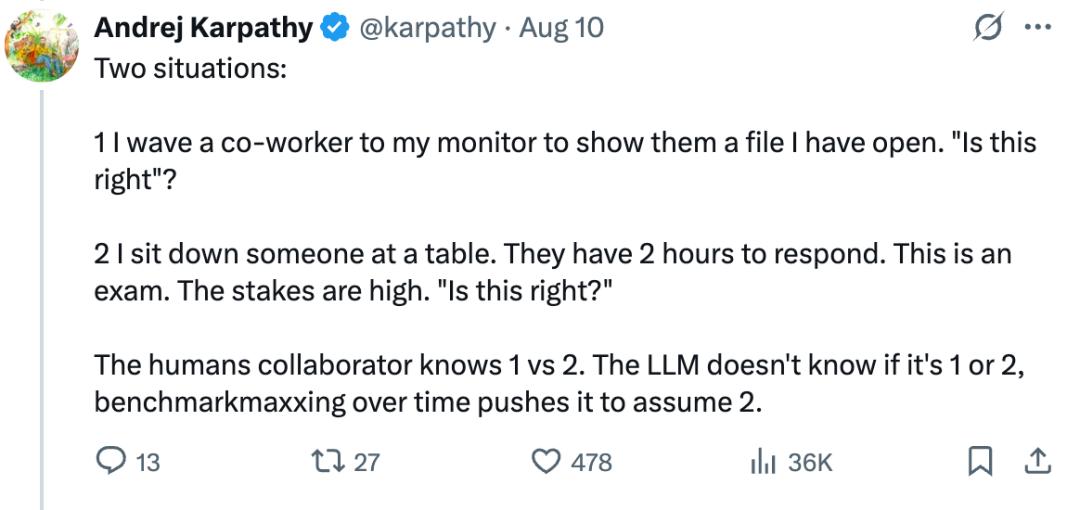
他指出了两种情境:
1. 我招待搭档过来看我屏幕上翻开的一个文件,问他「这样对吗?」
2. 我让或人坐在桌前,他们有 2 个小时来作答。这是一场考试, 危险很高。标题是「这样对吗?」
人类协作者能很自然地区别情境 1 和情境 2。但 LLM 并不知道你问的是 1 仍是 2,而跟着时刻推移、基准测验的不断「极限化」,它会越来越倾向于假定你问的是情境 2。
这指出了大模型过度考虑,杂乱化使命的或许原因,大模型的开展不能彻底以基准测验分数作为寻求。
关于大模型的「过度考虑」,有相关阅历和主意欢迎在谈论区别享。
本文来自微信大众号“机器之心”(ID:almosthuman2014),作者:冷猫,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

