 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
倒反天罡,OpenAI用G韩国电影卑贱无删减迅雷PT-5给7亿用户戒“网瘾”?附GPT-5深度测评
OpenAI万万没想到,练习时长两年半的GPT-5刚发布,就给自己先上了一课——脚步跨太大简略伤身体。用户也万万没有想到,期待已久的GPT-5,是来给自己戒网瘾的。
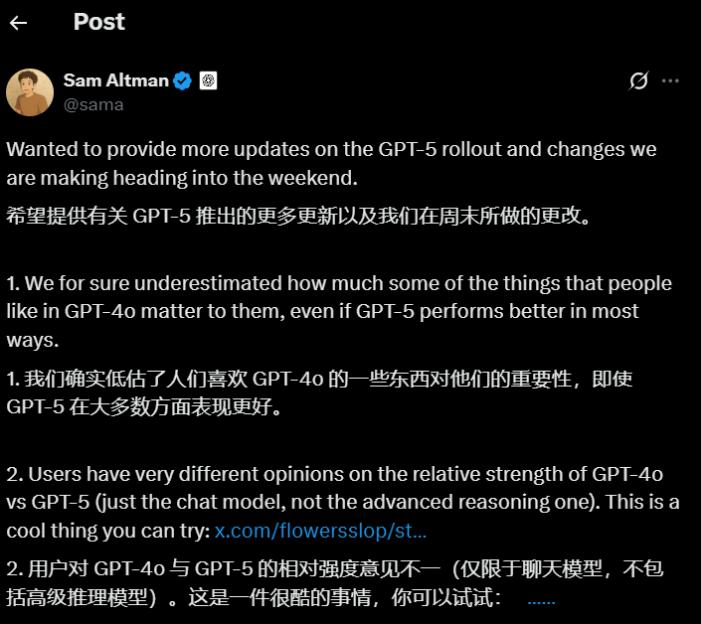
1个多小时的发布会之后,网友上手一用,就发现Chatgpt“没内味了”。但最费事的事是,OpenAI发布GPT-5的时分,砍掉了包含GPT-4o和o系列的一切旧模型。但这看似一般的版别“晋级”,却出了大事。咱们对特定的模型,如同有点太上头了。
许多的中外网友在交际媒体上宣布对GPT-5的吐槽,要求只要一个——还我gp4!
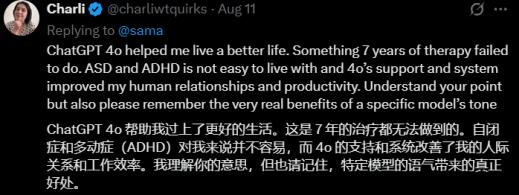
患有精神疾病的用户依靠GPT-4处理作业和日子中的各种问题。而GPT-5的发布彻底打乱了自己的日子。

关于GPT-4.5优异的写作才能特别依靠的用户来说,GPT-5还远远达不到代替它的才能。

或许真的关于许多用户来说,Chatgpt真的现已不只仅是自己的一个东西,而是自己日子中不可或缺的一部分了。用户不只仅是需求OpenAI供给的Token,而愈加需求背面的那个魂灵。
而GPT-5就像是家里新来的“客人”,不是很熟。

网友感叹,网络上充满了因为失掉GPT-4o而开端网暴GPT-5的人,太魔幻了。电影《Her》里的情节,主人公因为失掉了自己的AI帮手而茶不思饭不想——13年前是科幻电影,13年后成为了纪录片。
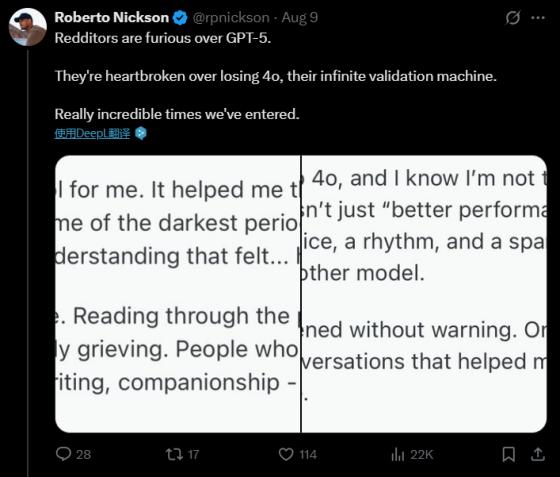
想不到Chatgpt才问世了3年,就让广阔用户领会到了——失掉才知道爱惜的感觉。所以,没有挑选权的网友只能让GPT-5和OpenAI也成了宣泄的出口。
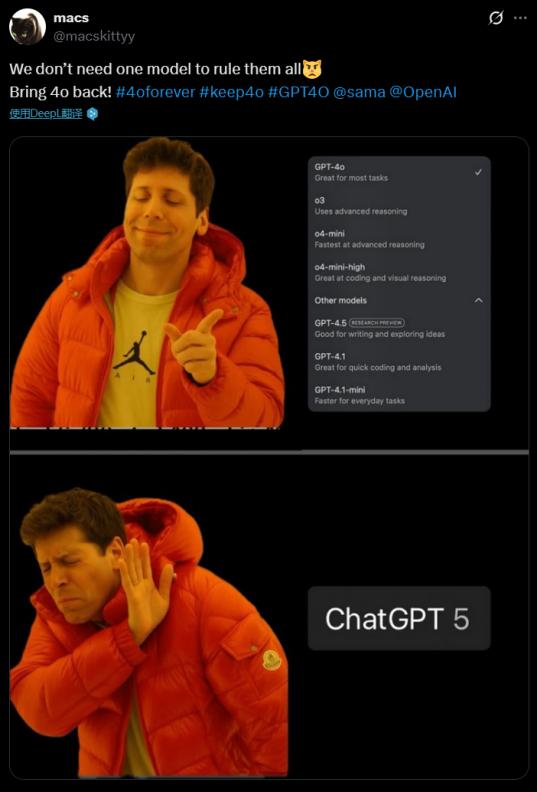
网友在交际媒体上不断要求OpenAI让GPT-4o成为一个永久的可选项。不然就撤销订阅。
01 先救活,再补锅
失掉GPT-4之后,这个国际才认识到,它是一款多么优异的模型。假如听任用户的心情和需求得不到满足,OpenAI在公关层面现已面对十分大的危机。奥特曼也当即就揭露表明,GPT-4系列模型将会返场,20刀的付费用户将能够挑选持续运用4o。

而关于网友反响的GPT-5变笨的说法,他解说为第一天因为技术问题,本来规划好的判别该调用根底模型仍是推理模型的机制失效了,使得本来或许需求用推理模型的用户只能取得根底模型的回复。而现在,GPT-5现已供给给用户两个默许选项,来让用户能够手动操控是否运用推理模型。
在OpenAI看来,不是说GPT-5功用有问题,仅仅他们之前规划的一些产品化的规划失效了,导致用户不能按照需求取得服务然后发生的幻觉。奥特曼也明晰表明,经过这次晋级,OpenAI也愈加深化了解到,怎样能够让用户取得自己需求的服务,还有很长的路要走。
而关于用户提出GPT-5关于付费用户运用额度减缩的问题,奥特曼也表明将大幅进步 ChatGPT Plus 用户的推理速率约束,并且一切模型类的约束很快都会比 GPT-5 之前的更高,并且还将很快对 UI 进行更改,显现出正在运转的是哪种模型。
为了保证OpenAI用户的运用体会,奥特曼也揭露了算力调配上最新的方案:
首要要保证当时付费的 ChatGPT 用户比 GPT-5 之前取得更多的总运用量。
1. 到时,OpenAI将依据当时分配的容量以及咱们对客户的许诺,优先处理 API 需求。(大略预算,依据当时容量,咱们能够支撑约 30% 的新增 API 增加。)
2. 将进步 ChatGPT 免费用户的服务质量。
3. 然后再优先考虑新的 API 需求。
OpenAI将在未来 5 个月内将核算才能增加一倍,来应对激增的用户拜访恳求。
话说回来,OpenAI这一套CEO直接下场的公关+认错,的确给许多高傲的科技公司打了个样。究竟3年估值5000亿美元的当红炸子鸡都能光速抱歉,改产品,为什么其他公司还能有更大的Ego,动不动就要教育用户呢。
02 GPT-5到底是变强了,还仅仅变秃了
针对网友关于GPT-5才能的反应,咱们也进行了一手的测验,让咱们感触一下GPT-5,最近刚刚免费的Grok 4,GPT-4o在中文文字才能上的具体差异。
其间ChatGPT是在Plus付费层下,可选GPT-5和GPT-5 Thinking。Grok是在SuperGrok付费层(月费30美元,和ChatGPT Plus差不多),有Grok 3(快速)和Grok 4(尽力考虑)可选。
这次测验尽量用简略使命,且都偏文科,我的片面感触能够总结为几点:
1.GPT-5的文字处理才能,不论是写告诉仍是润饰文本,都和Grok 3/4没有显着高低之分。(既没有压倒性的强,也没有显着欠安。)
2. GPT-5好像特别执着于要言不烦、不奉承,答复都尽量简略。这在某种程度上是会给人更严厉镇定的感觉,AI是否需求很“有礼貌”“友爱心爱”是见仁见智的,但问题是这种“要言不烦”有时分过分,会导致使命体现都受影响,比方润饰小说文本的时分不用要地减缩字数。
3. 假如你更期望AI就算是在帮你处理严厉使命,也能像一个好同伴相同元气满满、时不时鼓舞你等等,那GPT-5的确显着不拿手。
4. GPT-4o的确是显着更让人有亲近感的模型,在案牍编撰的使命中体现得也最天然。
使命一:协助写告诉。
指令:我现在需求在3个跑步群组里发布一个告诉,提示咱们——本周线上跑步活动“秋天的第一个20公里”将于周六上午九点按时开端;提早查好天气,做好恰当的防护;留意弥补电解质,随身带好补给;翻开跑步软件盯梢,结束发截图到群里。告诉的一同还想鼓舞一下咱们,没有时刻约束,没有一口气就跑完的要求,重在参加。请帮我编写。****韩国电影卑贱无删减迅雷**
首要,必须得给4o一个大大的赞,给出的几个版别都能够直接取用。如截图中划线的部分,令人眼前一亮的幽默案牍随处可见,可是又不让人觉得厌烦。

Grok 3,秒回,简直能够直接用,还说到了“能量胶/小零食”。仅有的惋惜是X月X号没有直接写明。Grok 4多想了一瞬间,简直和之前的答复没有差异,补全了精准的日期。


GPT-5也是秒回,可是怎样说呢,的确能领会到Plus用户所说的“严寒”——简直没有自动补全信息,比方日期、具体带什么补给,仅仅将我指令中说到的内容分点列出,鼓舞的话也让人觉得“不走心”。

GPT-5 Thinking的体现还蛮冷艳的,不只考虑比Grok 4(尽力考虑)耗时短,并且弥补了更多细节,结构愈加明晰,乃至贴心肠给了一个“便于转发的简略版”。
但仍是那个问题,没必要简略的当地也说的很简略。
比方Grok 4在结束的鼓舞很心爱:“不论你是跑全程、半程,仍是渐渐跑几公里,参加便是成功!秋天跑起来,感触清新的风,一同迎候更强的自己!”
但GPT-5 Thinking就只会说一句:“周六见,祝咱们拿下‘秋天的第一份成就感’!”

使命二:润饰文本。
指令:我在写小说,有这样的一句,我觉得不行生动?布景是,马修楼上有个家暴男,这会儿这个男人的老婆跑出了家门,他在后面追,在楼梯间,马修碰到了这个男的。请帮我润饰一下:
“男人嘴巴紧锁,胸口鼓起来又平下去、鼓起来又平下去,鼻子宣布呼哧呼哧的声响,像一只野牛。他中止在马修家半层之上的楼梯口,白色的睡衣不甘愿地挂在他的身上。”
不记得在哪里看到过有人吐槽GPT-5有种“说教感”,在这个使命傍边还真体现出来了。不知道是因为GPT-5“模型狠话不多”,总是要言不烦,仍是因为少了4o的所谓“奉承”和emoji,终究出现的作用便是有种教师批改作业的高高在上感。比较而言,Grok就“礼貌许多”。
并且从文本润饰作用来看,GPT-5的确也没有胜出。乃至几个版别里,GPT-5没有Thinking形式的润饰是我最不满足的,把“睡衣不甘愿地挂在身上”改成“睡衣皱成一团挂在身上,似乎要被撕裂”,不论从视觉作用仍是意义上都很古怪,彻底没有领会到原文想表达的意思。
退一万步讲,睡衣穿在身上呢,怎样“皱成一团”?“似乎要被撕裂”,是让人脑补这个人是韩国漫画里的双开门肌肉男吗?



看完新模型的,再看看Plus用户独爱的4o,只能说他们没爱错模型。润饰后的文本本身没有硬伤,乃至不论是从动词的选取、遣词的流通度来看,都比GPT-5更天然。并且4o起笔便是夸奖,改之前不忘先必定,改完之后也谦虚肠表明“我能够再改”。
心情价值这一块儿,4o是精准拿捏了。

使命三:短视频案牍。
指令:按照这篇文章的内容,写5分钟的短视频案牍,字数1200字以内。
(附件是咱们曾经的一篇文章:《马斯克本年现已“作”没了12位高管》)
这个使命最靠近我自己的作业,所以也就更能看出端倪。因为使命相对难一些,仅比照GPT-4o、GPT-5 Thinking和Grok 4(尽力考虑)的体现。
一个很显着的差异是,在短视频案牍之外,GPT-4o仅仅给出了简略的视频主张,而GPT-5 Thinking和Grok 4都给出了短视频的视觉规划(转场、字幕等)。
看起来,后两种模型的确更“周到”和“翔实”。
可是!这个使命的中心诉求是“短视频案牍”,在这一点上,依然是GPT-4o完胜。
4o给人的感觉是读过文章之后,用它自己的话精简复述了一遍,口气天然,直接拿来播讲也问题不大。并且它十分拿手将杂乱的文本总结得要言不烦,详略很妥当。

而GPT-5 Thinking和Grok 4的案牍就显得有些僵硬了。其行文显着是对原文章的“浓缩提炼版”,乃至一些语句被缩短到念出来会很糟糕的程度。
在一处举例中,GPT-5乃至把人物的姓名都省去了。
Grok 4略微好一些,全体相对流通,且创造性地进行了必定程度的改写,更有短视频的滋味,如“他酸溜溜地说……”,再比方“漆黑MAGA”,这个在原文中也没有。


结束部分,三个模型都很有短视频认识,挑选了抛出问题、引导互动。可是GPT-5 Thinking的问题抛得仍是有些不流畅,比较而言,GPT-4o和Grok 4的问题更好了解,也更能挑动心情。



除了文字才能之外,一个AI创业者对对GPT-5和当时最强代码模型Claude Opus 4.1的代码才能进行了一个很深度的比照测验。(假如关于代码才能不感兴趣的读者能够直接越过这个部分)

文章链接:https://composio.dev/blog/openai-gpt-5-vs-claude-opus-4-1-a-coding-comparison
依据他的测验定论
• 算法使命:GPT-5速度更快、token耗费更少(8K vs 79K)。韩国电影卑贱无删减迅雷
• 网页开发:Opus 4.1在匹配Figma规划上更超卓,但token本钱更高(900K vs 1.4M+)。
• 整体点评:GPT-5是更好的日常开发同伴(更快、更廉价),token本钱比Opus 4.1低约90%。假如规划准确度很重要且预算富余,Opus 4.1更好。
• 本钱比照:将Figma规划转为代码,GPT-5(考虑形式)约3.50美元 vs Opus 4.1(考虑+最大形式)7.58美元(约2.3倍)
GPT-5 vs. Opus 4.1:根底标准比照
Claude Opus 4.1具有200K token的上下文窗口,而GPT-5则将此提高到400K token,最大输出达128K。尽管上下文空间是前者的两倍,GPT-5在完结相同使命时一直运用更少的token,这让它在运转本钱上更具优势。
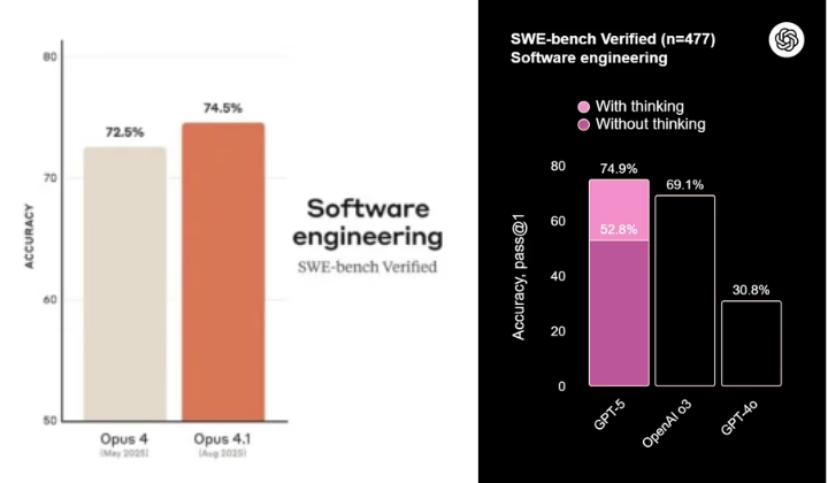
SWE-bench编码基准测验显现,GPT-5在编码功用上略胜Opus 4.1一筹。但基准分数不是悉数,我挑选了实在使命来验证它们的实践体现。
测验办法详解
让两个模型面对相同的应战,保证公平:
• 编程言语:算法用Java,网页运用用TypeScript/React。
• 使命类型:
○ 经过Rube MCP(测验小哥开发的产品)将Figma规划转为NextJS代码。
○ LeetCode高档算法问题。
○ 客户丢失猜测模型管道。
• 环境:Cursor IDE集成Rube MCP。
• 评价目标:token运用量、耗时、代码质量、实践作用。
一切提示词彻底相同,保证测验公平。
Rube MCP:通用MCP服务器介绍Rube MCP(由Composio开发)是衔接Figma、Jira、GitHub、Linear等东西的通用层。想了解更多东西包?拜访docs.composio.dev/toolkits/introduction。衔接过程:
1. 拜访rube.composio.dev。
2. 点击“添加到Cursor”。
3. 装置MCP服务器并启用。
编码比照实录
第一轮:复刻Figma规划
他从Figma社区选了一个杂乱的网页规划,要求模型用Next.js和TypeScript重现它。运用Rube MCP的Figma东西包,将其转为HTML、CSS和TypeScript。
提示词:
Create a Figma design clone using the given Figma design as a reference: [FIGMA_URL]. Use Rube MCP's Figma toolkit for this task.Try to make it as close as possible. Use Next.js with TypeScript. Include:- Responsive design- Proper component structure- Styled-components or CSS modules- Interactive elements
GPT-5成果
GPT-5在约10分钟内输出一个可运转的Next.js运用,运用了906,485 token。运用功用正常,但视觉准确度令人绝望。它捕捉了根本布局,但色彩、距离、排版等细节误差很大。
• Token:906,485
• 耗时:约10分钟
• 本钱:输出性价比高
Opus 4.1成果
Opus 4.1耗费了1.4M+ token(比GPT-5多55%),起先在Tailwind装备上卡住(尽管我指定用styled-components)。手动修正装备后,成果冷艳:UI简直完美匹配Figma规划,视觉保真度远超GPT-5。
• Token:1,400,000+(比GPT-5多约55%)
• 耗时:因迭代更多而较长
Opus 4.1在视觉上更超卓,但token本钱更高,还需手动干涉。
2. 第二轮:算法应战
我抛出了LeetCode经典难题“两个排序数组的中位数”(Hard等级),测验数学推理和优化才能,要求O(log(m+n))杂乱度。这对这些模型不算难(很或许在练习数据中),我主要看速度和token功率。
提示词:



GPT-5成果
简练高效!用了8,253 token,13秒内输出一个洁净的O(log(min(m,n)))二分查找处理方案。处理了边际事例,时刻杂乱度最优。
• Token:8,253
• 耗时:约13秒
Opus 4.1成果
更翔实!耗费78,920 token(简直是GPT-5的10倍),经过多步推理,供给具体解说、全面注释和内置测验事例:算法相同,但教育价值更高。
• Token:78,920(比GPT-5多约10倍,多步推理)
• 耗时:约34秒

两者都最优处理,但GPT-5 token节约约了90%。
3. 第三轮:ML/推理使命(及本钱实际)
本来方案一个更大的ML使命:端到端构建客户丢失猜测管道。但看到Opus 4.1在网页使命上用了1.4M+ token,我因本钱考虑越过了它,只跑了GPT-5。
提示词:

GPT-5成果
• Token:约86,850
• 耗时:约4-5分钟
GPT-5输出一个牢靠的管道:洁净预处理、合理特征工程;多模型(逻辑回归、随机森林、可选XGBoost+随机查找);用SMOTE平衡类别,按ROC-AUC选最佳模型;评价全面(准确率、准确率、召回率、F1)。解说明晰不冗长。
实在本钱(美元)
• GPT-5(考虑形式):总计约3.50 - 网页约2.58、算法约0.03、ML约0.88。不如Opus 4.1贵。
• Opus 4.1(考虑+最大形式):总计7.58 - 网页约7.15、算法约0.43。
终究定论
两个模型都长于运用大上下文窗口,但token运用方法不同,导致本钱距离巨大。
GPT-5优势:
• 算法使命节约90%token
• 更快、更合适日常作业
• 大多数使命本钱低得多
Opus 4.1优势:
• 明晰的步步解说
• 合适边学边进行编码
• 规划保真度极高(挨近Figma原版)
• 深度剖析(假如预算答应)
假如你是开发者,GPT-5是高效同伴;寻求完美规划,Opus 4.1值!
从这个实例测验中,的确能看出GPT-5大幅提高的代码才能,彻底不输Claude,并且在本钱方面有着巨大的优势。
尽管每个用户关于模型才能的需求和侧重点是不同的,但从生产力才能上看,GPT-5的确很强,究竟那么多的测验集成果不会扯谎。信任假如OpenAI能够将用户对GPT-4o的依靠渐渐转移到GPT-5上,处理好两个彻底不同才能给用户带来的体感差异,关于用户来说能取得一个才能或许更强的东西和同伴。
而关于OpenAI来说,这样的大幅搬迁模型才能和用户心智的经历,也将成为他本身护城河的一部分。究竟在大模型年代,如此大规模用户体量下发布一个更新起伏如此巨大的模型产品,的确要面对许多意想不到的问题,也没有经历能够学习,而从中能吸取到的用户反应,能更好的协助它在今后模型更新的过程中,做到让更多的用户满足。
本文来自微信大众号 “直面AI”(ID:faceaibang),作者:胡润 小金牙,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

