 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
西游记浙版在线播放相同聚集生物声学范畴
Google DeepMind 与 Google Research 联合推出的 Perch 2.0,进一步将生物声学研讨面向新高度。相较于前代,Perch 2.0 以物种分类为中心练习使命,不只纳入了更多非鸟类类群的练习数据,还选用了全新的数据增强战略与练习方针,在 BirdSET 和 BEANS 两项威望生物声学基准测验中均改写当时 SOTA。
生物声学作为衔接生物学与生态学的重要东西,在生物多样性维护与监测中扮演着要害人物。前期研讨多依靠模板匹配等传统信号处理手法,在杂乱天然声学环境与大规划数据面前,逐步露出功率低下、准确性缺乏的限制。
近年来,人工智能技能的爆发式开展推进深度学习等办法代替传统手法,成为生物声学事情检测与分类的中心东西。例如,根据大规划带标签鸟类声学数据练习的 BirdNET 模型,在鸟类声纹辨认中体现杰出:不只能精准区别不同物种的鸣叫,还能在必定程度上完成个别辨认。此外,Perch 1.0 等模型经过持续优化迭代,在生物声学范畴堆集了丰厚作用,为生物多样性监测与维护供给了坚实的技能支撑。
日前,Google DeepMind 与 Google Research 联合推出的 Perch 2.0,进一步将生物声学研讨面向新高度。相较于前代,Perch 2.0 以物种分类为中心练习使命,不只纳入了更多非鸟类类群的练习数据,还选用了全新的数据增强战略与练习方针。该模型在 BirdSET 和 BEANS 两项威望生物声学基准测验中均改写当时 SOTA,彰显出强壮的功能潜力与宽广的运用远景。
相关研讨作用以「Perch 2.0: The Bittern Lesson for Bioacoustics」为题,宣布预印本于 arXiv。
论文地址:https://arxiv.org/abs/2508.04665
数据集:练习数据构建与评价基准
该研讨为模型练习整合了 4 个带标签音频数据集——Xeno-Canto、iNaturalist、Tierstimmenarchiv 和 FSD50K,一起构成模型学习的根底数据支撑。其间,如下表所示,Xeno-Canto 与 iNaturalist 是大型公民科学库:前者经过揭露 API 获取,后者源自 GBIF 渠道标记为研讨级的音频,二者均包括很多鸟类及其他生物的声学录音;Tierstimmenarchiv 作为柏林天然历史博物馆的动物声响档案,相同聚集生物声学范畴;而 FSD50K 则弥补了多种非鸟类声响。
这四类数据共包括 14,795 个类别,其间 14,597 个为物种,其他 198 个为非物种声响事情。丰厚的类别掩盖既保证了对生物声学信号的深度学习,又经过非鸟类声响数据拓宽了模型的适用规划。不过,因为前三个数据集选用不同的物种分类体系,研讨团队人工映射一致了类别称号,并除掉了无法用选定频谱图参数标明的蝙蝠录音,以此保证数据的一致性与适用性。
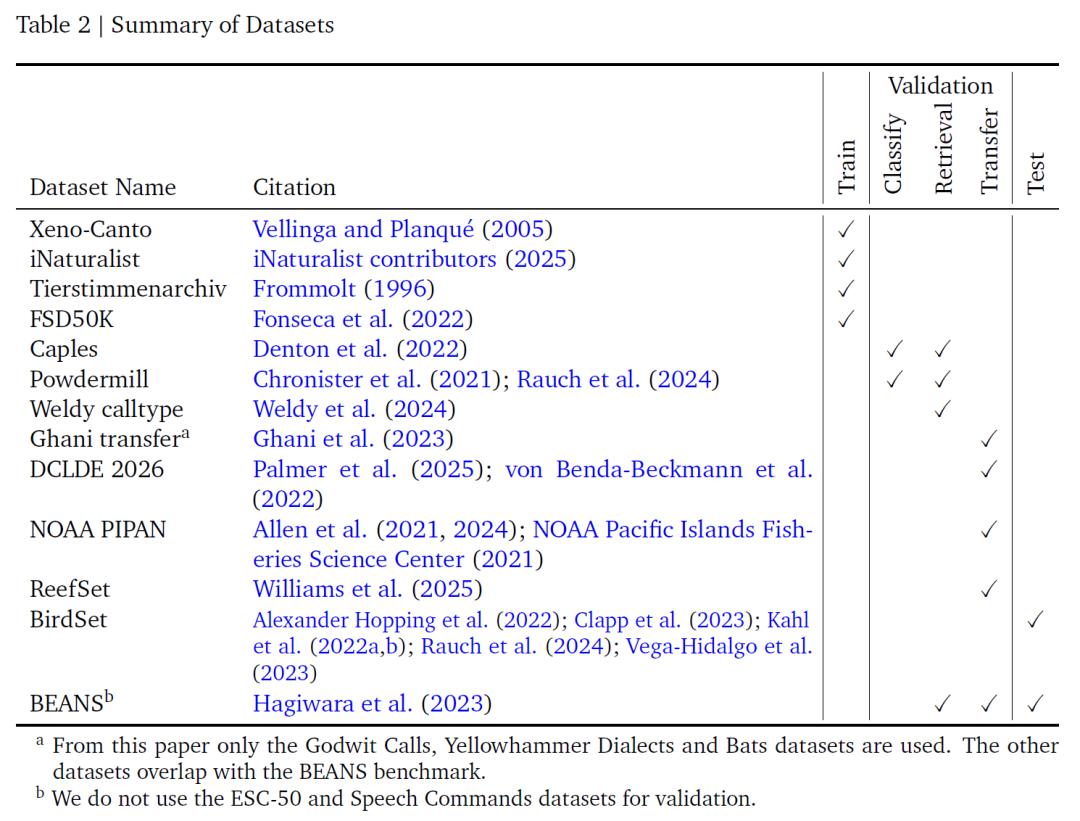
数据集摘要
考虑到不同数据源的录音时长差异极大(从缺乏 1 秒到超越 1 小时,大都在 5–150 秒),而模型固定以 5 秒片段为输入,研讨团队规划了两种窗口选取战略:随机窗口战略在选中某条录音时随机截取 5 秒,虽或许包括方针物种未发声的片段,带来必定标签噪声,但全体处于可接受规划;能量峰值战略则沿袭 Perch 1.0 的思路,经过小波改换选出录音中能量最强的 6 秒区域,再从中随机选取 5 秒,根据「高能量区域更或许包括方针物种声响」的假定提高样本有用性——这一办法与 BirdNET 等模型的检测器规划逻辑相通,能更精准捕捉有用声学信号。
为进一步提高模型对杂乱声学环境的适应才能,研讨团队选用了 mixup 的数据增强变体,经过混合多条音频窗口生成复合信号:先从 Beta-二项散布采样确认混合的音频条数,再经过对称 Dirichlet 散布采样权重,对选中的多条信号进行加权求和并标准化增益。
与原始 mixup 不同,该办法选用多热方针向量而非 one-hot 向量的加权均匀,保证窗口内一切发声(不管响度凹凸)都能被高置信度辨认;相关参数作为超参数调优,可增强模型对堆叠声响的分辩才能,提高分类准确性。
模型评价则依托 BirdSet 与 BEANS 两大威望基准打开。西游记浙版在线播放BirdSet 包括来自美国本乡、封面有男天全集在线播放夏威夷、秘鲁、哥伦比亚的 6 个全标示声景数据集,评价时不进行微调,直接选用原型学习分类器的输出;BEANS 包括 12 项跨类群测验使命(触及鸟类、陆生与海洋哺乳动物、无尾目及昆虫),仅用其练习集练习线性与原型探针,相同不调整嵌入网络。
Perch 2.0:一种高功能的生物声学预练习模型
Perch 2.0 的模型架构由前端(frontend)、嵌入网络(embedding model)和一组输出面(output heads)一起构成,各部分协同完成从音频信号到物种辨认的完好流程。
其间,前端担任将原始音频转换为模型可处理的特征方法,其接纳 32kHz 采样的单声道音频,针对 5 秒长的片段(含 160,000 个采样点),经过 20ms 窗长、10ms 跳长的处理,生成包括 500 帧、每帧 128 个 mel 频带的 log-mel 频谱图,掩盖 60Hz 到 16kHz 的频率规划,为后续剖析供给根底特征。
嵌入网络选用 EfficientNet-B3 架构——这是一款包括 1.2 亿参数的卷积残差网络,凭仗深度可别离卷积规划最大化参数功率。相比上一版别 Perch 运用的 7,800 万参数 EfficientNet-B1,它的规划更大,以匹配练习数据量的添加。
经过嵌入网络处理后,会得到形状为(5, 3, 1536)的空间嵌入(维度别离对应时刻、频率和特征通道),对空间维度取均值后,可获得 1536 维的大局嵌入,作为后续分类的中心特征。
输出面则承担着详细的猜测与学习使命,包括 3 个部分:线性分类器将大局嵌入投影到 14,795 维的类别空间,经过练习促进不同物种的嵌入线性可分,提高后续适配新使命时的线性勘探作用;原型学习分类器以空间嵌入为输入,为每个类别学习 4 个原型,取原型最大激活进行猜测,这一规划源自生物声学范畴的 AudioProtoPNet;来历猜测头是一个线性分类器,根据大局嵌入猜测音频片段的原始录音来历,因为练习集包括 150 余万条来历录音,它经过秩为 512 的低秩投影完成高效核算,服务于自监督来历猜测丢失的学习。
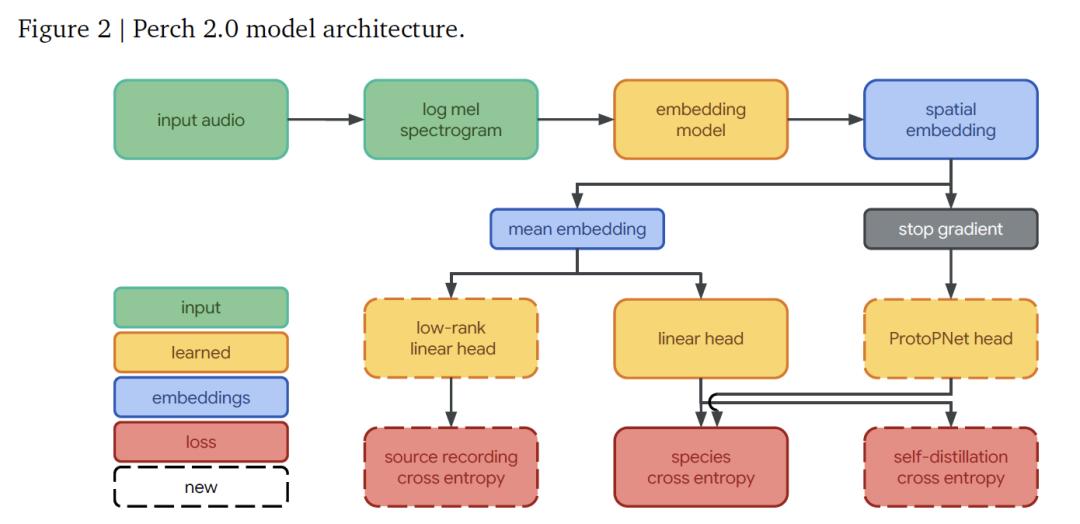
Perch 2.0 模型体系结构
模型练习经过 3 个独立方针完成端到端优化:
* 物种分类穿插熵针对线性分类器,选用 softmax 激活和穿插熵丢失,对方针类别赋予均匀权重;
* 自蒸馏机制中,原型学习分类器作为「teacher」,其猜测成果辅导「student」线性分类器,一起经过正交丢失最大化原型差异,且梯度不回传至嵌入网络;
* 来历猜测作为自监督方针,将原始录音视为独立类别练习,推进模型捕捉明显特征。
练习分两阶段:第一阶段专心练习原型学习分类器(不发动自蒸馏,最多 300,000 步);第二阶段发动自蒸馏(最多 400,000 步),均运用 Adam 优化器。
超参数挑选(Hyperparameter selection)依托 Vizier 算法,第一阶段查找学习率、dropout 率等,经两轮挑选确认最优模型;第二阶段添加自蒸馏丢失权重持续查找,两种窗口采样方法贯穿一直。
成果显现,第一阶段偏好混合 2-5 条信号,来历猜测丢失权重 0.1-0.9;自蒸馏阶段倾向小学习率、少用 mixup,赋予自蒸馏丢失 1.5-4.5 的高权重,这些参数支撑了模型功能。
Perch 2.0 的泛化才能评价:基准体现与实用价值
Perch 2.0 的评价聚集泛化才能,既调查其在鸟类声景(与练习录音差异明显)、非物种辨认使命(如叫声类型辨认)中的体现,也测验向蝙蝠、海洋哺乳动物等非鸟类类群的搬迁才能。考虑到从业者常需处理少数或无标签数据,评价中心原则是验证「冻住嵌入网络」的有用性,即经过一次性提取特征,快速适配聚类、小样本封面有男天全集在线播放9;游记浙版在线播放学习等新使命。
模型挑选阶段从 3 方面验证实用性:
* 预练习分类器功能,在全标示鸟类数据集上用 ROC-AUC 评价「开箱即用」的物种猜测才能;
* 一次样本检索,以余弦间隔衡量聚类与查找体现;
* 线性搬迁,模仿小样本场景测验适配才能。
这些使命经过几许均值核算得分,终究 19 个子数据集的成果反映了模型实在可用性。
依托 BirdSet 与 BEANS 两大基准,该研讨的评价成果如下表所示,Perch 2.0 在多项方针上体现杰出,特别 ROC-AUC 达当时最佳,且无需微调;其随机窗口与能量峰值窗口练习战略功能挨近,估测因自蒸馏缓解了标签噪声影响。
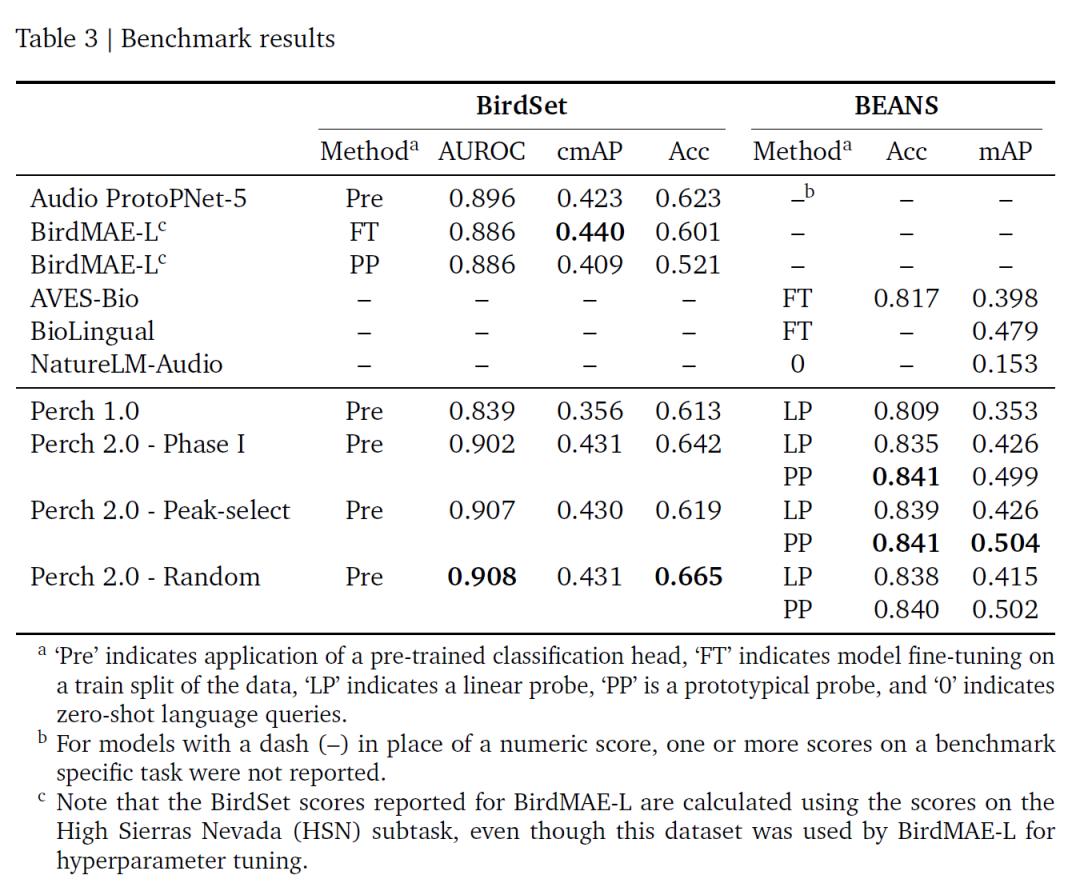
基准测验成果
整体而言,Perch 2.0 以监督学习为中心,与生物声学特性密切相关。Perch 2.0的打破标明,高质量搬迁学习无需依靠超大模型,精密调优的监督模型结合数据增强与辅佐方针即可体现优异。其固定嵌入规划(无需重复微调)降低了大规划数据处理本钱,为灵敏建模供给或许。未来,构建贴合实践的评价基准、使用元数据开发新使命、探究半监督学习,将是该范畴的重要方向。
生物声学与人工智能的交汇
在生物声学与人工智能穿插范畴,跨类群搬迁学习、自监督方针规划、固定嵌入网络优化等研讨方向已引发全球学术界与企业界的广泛探究。
剑桥大学团队开发的余弦间隔虚拟对立练习(CD-VAT)技能,经过一致性正则化提高声学嵌入的区别性,在大规划说话者验证使命中康复了 32.5% 的等错误率改善,为语音辨认中的半监督学习供给了新范式。
麻省理工学院与 CETI 协作的抹香鲸声纹研讨,经过机器学习别离出包括节奏、韵律、震颤和装饰音的「发音字母表」,提醒其沟通体系的杂乱性远超预期——仅东加勒比抹香鲸部族就存在至少 143 种可区别的发声组合,其信息承载才能乃至超越人类言语的根底结构。
苏黎世联邦理工学院研制的光声成像技能,经过负载氧化铁纳米颗粒的微胶囊打破声学衍射极限,完成深层安排微血管的超分辩率成像(分辩率达 20 微米),在脑科学与肿瘤研讨中展现出多参数动态监测的潜力。
一起,开源项目 BirdNET 凭仗全球 1.5 亿条录音的堆集,已成为生态监测的标杆东西,其轻量级版别 BirdNET-Lite 可在树莓派等边际设备上实时运转,支撑超越 6,000 种鸟类的辨认,为生物多样性研讨供给了低本钱解决计划。
日本 Hylable 公司在日比谷公园布置的 AI 鸟鸣辨认体系,经过多麦克风阵列与 DNN 结合,完成声源定位与品种辨认的同步输出,准确率达 95% 以上,其技能结构已扩展至城市绿地生态评价与无障碍设备建造范畴。
值得重视的是,谷歌 DeepMind 的 Project Zoonomia 项目正经过整合 240 种哺乳动物的基因组与声学数据,探究跨物种声学共性的进化机制。研讨发现,犬类愉悦吠叫的谐波能量散布(3-5 次谐波能量比 0.78±0.12)与海豚交际哨声(0.81±0.09)高度同源,这种分子生物学层面的相关不只为跨物种模型搬迁供给了根据,更启发了“生物学启发式AI”的全新建模途径——将进化树信息融入嵌入网络练习,然后打破传统生物声学模型的限制性。
这些探究正在让生物声学与人工智能的结合变得更有温度。当学术探究的深度遇上工业运用的广度,那些曾藏在雨林树冠、深海暗礁里的生命信号,正被更明晰地捕捉、解读,终究化作维护濒危物种的行动指南,或是城市与天然调和共生的才智计划。
参阅链接:
1.https://mp.weixin.qq.com/s/ZWBg8zAQq0nSRapqDeETsQ
2.https://mp.weixin.qq.com/s/UdGi6iSW-j_kcAaSsGW3-A
3.https://mp.weixin.qq.com/s/57sXpOs7vRhmopPubXTSXQ
本文来自微信大众号“HyperAI超神经”,作者:田小幺,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

