 荆州市城市管理执法委员会
荆州市城市管理执法委员会
政府信息公开
刚刚,OpenAI内部推理老九门无删减版 下载模型斩获IOI 2025金牌,一切AI选手中榜首
OpenAI的内部推理模型,又拿下了IOI 2025金牌,打败325名人类选手,总排名第6,AI组第1。该模型沿袭IMO金牌版别,无专门练习,限时5小时、50次提交且无联网支撑。
刚刚,OpenAI内部推理模型在取得IMO金牌后,又拿下了IOI金牌。
和前次IMO相同,OpenAI 运用了草莓形象来代表这个推理模型。
只不过这次的「草莓」不只带上了IOI的金牌,而且愈加的拟人,这个形象很有或许进化为OpenAI内部推理体系代表形象。

OpenAI宣言的这个「内部推理体系」便是前次拿下IMO金牌,惹出争议的同款模型。
IMO之后,OpenAI对IMO金牌模型进行了全面评价,发现除了数学比赛之外,它在许多其他范畴(包含编程)也是现在最好的模型。
因而,OpenAI决议直接运用完全相同的IMO金牌模型,不做任何更改,并将其使用于IOI的体系中。

OpenAI官方也发帖证明了这个音讯。
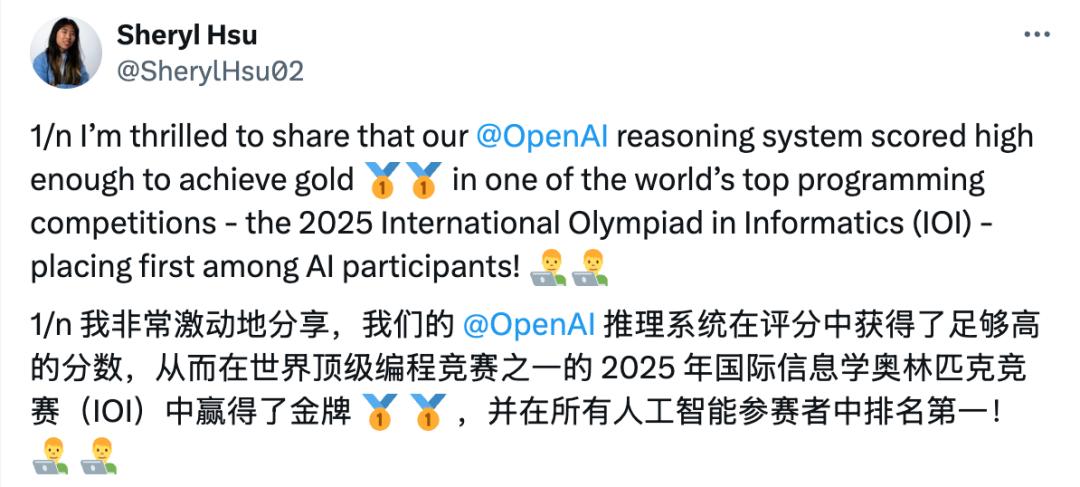
这个内部推理模型的得分足够高,在本年的IOI线上比赛中,和人类一同排名位列第6,与其他AI排名则是第1。

Sheryl Hsu表明,这次内部模型参加了IOI的在线AI比赛项目,总共330位参赛选手。
前5位都是人类。
此次比赛,AI和人类参赛者相同,相同的5小时时刻约束,以及最多50次的提交约束次数。
而且,和人类相同,这个推理体系没有「联网」,也没有「RAG」查找,老九门无删减版 下载只能拜访根本的终端东西。
这个推理模型并没有针对IOI进行特别练习。
也便是说,除了让模型连接到IOIAPI外,剩余的一切都靠AI自己推理。
其实上一年,OpenAI就参加过IOI比赛,其时以稍微低于铜牌分数线的成果收尾。
只是曩昔一年时刻,推理模型的排名就从第49百分位跃升到第98百分位。

OpenAI内部推理模型-IOI金牌团队
不过,就在该音讯发布没有多久。
马斯克的Grok也来搅局了!
首要要清晰的是,这个「内部推理模型」并不是To C的模型,除了OpenAI内部,没有人可以拜访。
那像现在最尖端的商业模型,在IOI上体现怎么?
答案是:不忍目睹。
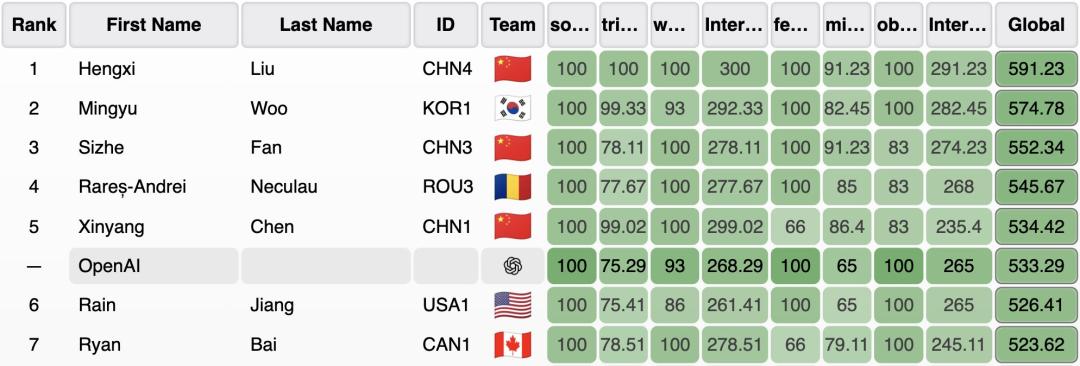
依据Vals AI的测验成果,现在能在IOI取得抢先的商业模型,居然是Grok 4。

首要,现在一切的顶尖模型都存在显着缺乏,没有一个模型能在恣意一年的比赛中取得奖牌。
Grok 4以26.2%的准确率抢先,随后是GPT-5、Gemini 2.5 Pro和Claude Opus 4.1。
Vals AI经过其揭穿端点进行测验,一切商业模型在IOI上仍有很大的改善空间。
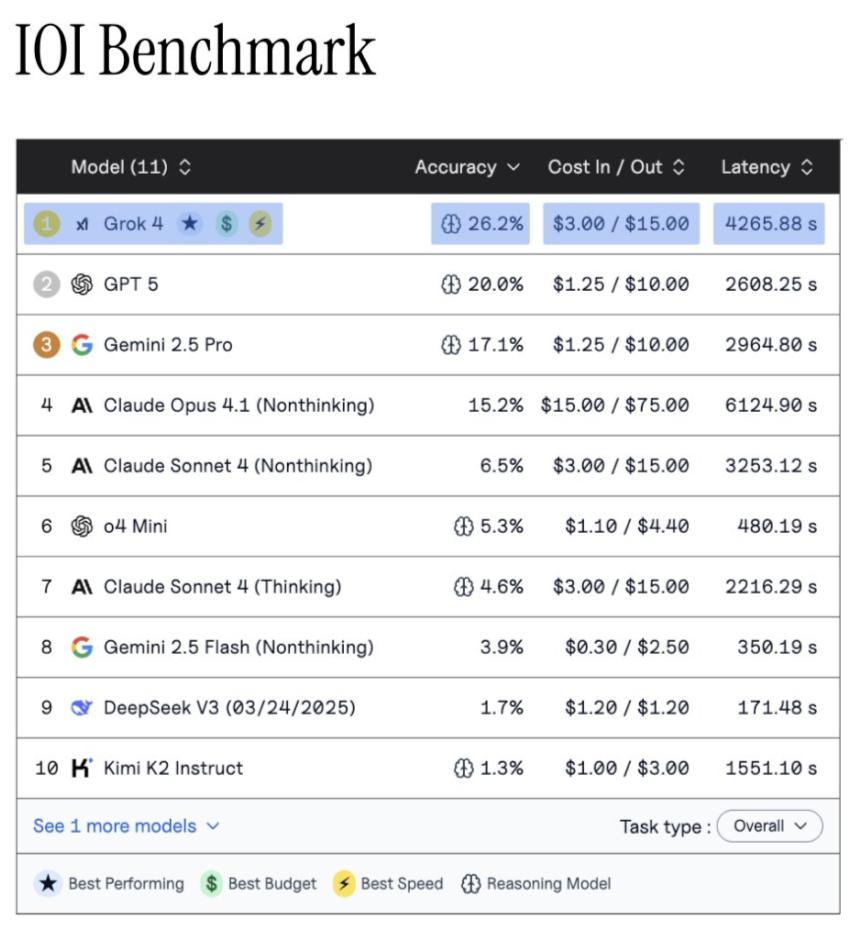
此外Vals AI这次测验中发现,「贵便是好」的道理也适用于大模型范畴。
只要每道问题超越2美元的贵重模型,才干取得有意义的体现。

也便是说,OpenAI试验室里的那个推理模型,要远远强过现在大众可以接触到的商业模型。

这或许给人们带来许多遥想,现在最顶尖试验室中的最先进的AI技能间隔大众还有多远?
这引发了许多猜想和评论。
从IMO金牌闹剧中可以看到,巨子们关于这种「抢先地位」的寻求十分强。
谷歌Gemini为了给自己正名为「首个取得IMO金牌的AI模型」,乃至有组委会出头宣告「OpenAI的宣告」是无效的。老九门无删减版 下载
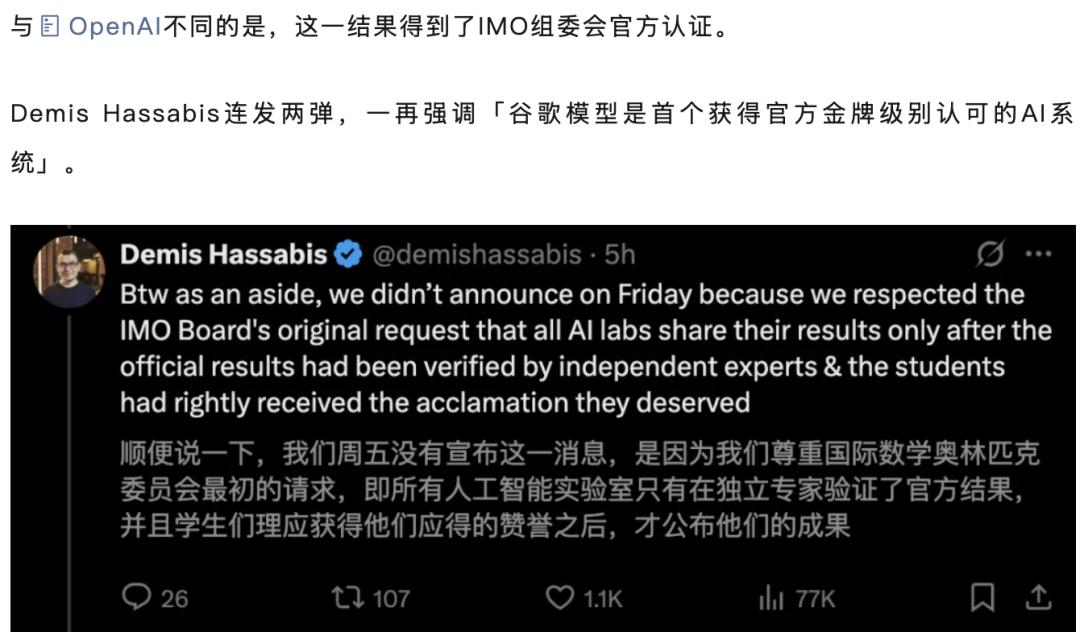
乃至还有OpenAI被曝IMO金牌造假,陶哲轩揭穿内情的桥段。
现在GPT-5刚刚发布,OpenAI就立刻宣告IOI金牌,可以猜测,这应该便是给后来的Gork 5和Gemini 3等模型预备的应战。
为何OpenAI、谷歌、Anthropic、Grok等巨子们痴迷于刷榜和比赛通关?
巨子们对刷榜和比赛排名的痴迷,根本上源自AI职业的高度竞赛性和技能的快速迭代。
首要,刷榜是最直接有用的营销手法之一。
排名榜单上的抢先方位不只意味着技能优势,更代表了商场影响力和品牌认可度。一旦模型在威望比赛如IMO、IOI中斩获佳绩,企业便能敏捷建立强壮的品牌形象,招引大众重视并提高用户信赖。
其次,AI范畴的比赛排名一般与模型的通用功能和使用潜力高度相关。无论是IMO仍是IOI,这些比赛检测的是模型的根底推理、逻辑推演和泛化才能。
换句话说,比赛胜出代表着模型不只在特定使命上体现优异,更意味着其在更广泛的使用场景中或许具有抢先的技能优势。
最终,比赛胜出可以大大提高对人才和本钱的招引力。
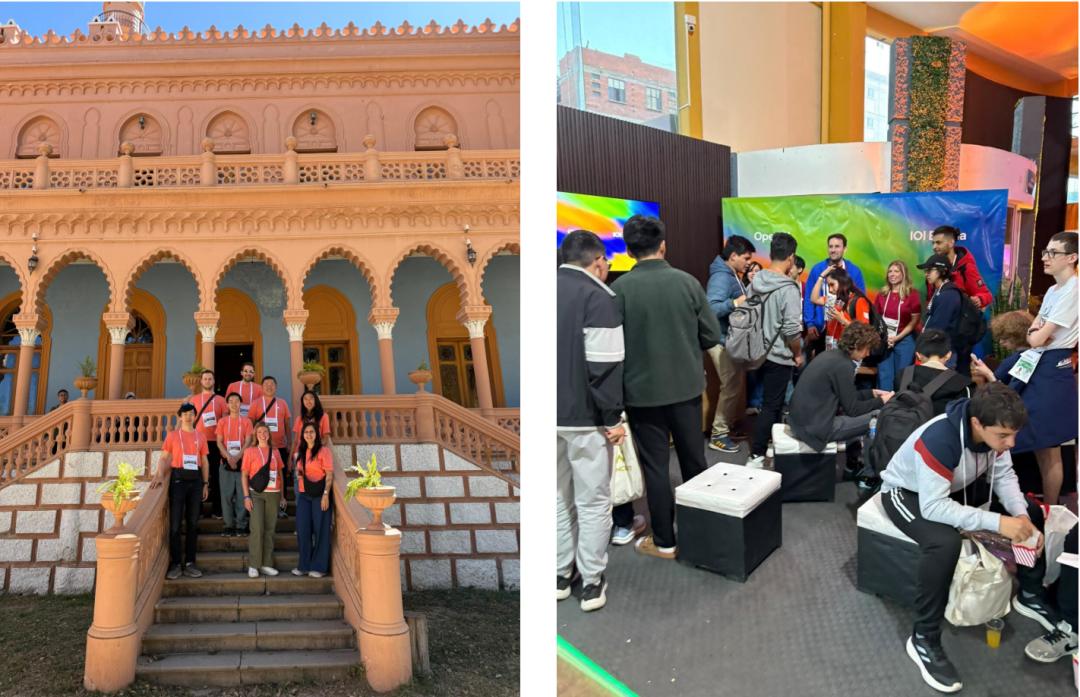
OpenAI团队前往玻利维亚亲自参加IOI
正因如此,OpenAI、谷歌DeepMind、Meta和Anthropic等AI巨子一向热衷于在比赛上彼此比赛,每一次榜单的变化都或许影响AI职业未来的格式。
那么,谁是地表最强AI?
或许这个竞赛会一向继续到咱们完成AGI的那天吧。
参考资料
https://x.com/SherylHsu02/status/1954966118680105150
本文来自微信大众号“新智元”,作者:定慧,36氪经授权发布。
相关附件
荆州市城市管理执法委员会主办荆州新闻网承办
地址:湖北省荆州市沙市区北京西路307号
联系电话:0716-8270890传真:
鄂ICP备05028271号鄂公网安备 42100202000246号网站标识码:4210000057

